A Theory of Arrays (ToA) Union Find
One thing I’ve been discussing with Rudi, Michel and Max is union find annotations. Union find enhancements that still feel like union finds.
I think I have another one that supports a notion of destructive store / substitution which doesn’t obviously fall into previous categorizations. Such an edge annotation feels highly noninvertible, but it is ultimately doable because the edge annotation is nondestructively swapping out data with the root annotation during rerooting.
Annotating Union Finds
There are some places in the union find it is possible to put little extra bits of data.
One can annotate the root with data. When you merge two classes, you need some method to merge this data. This binary operation probably should be commutative and perhaps idempotent, which puts it in the ball park of a semigroup / semilattice. In egg, this mechanism is used to store program analyses. Sometimes people use them to store counts in the sets, which are not a semilattice. I kind of liked the “union find dict” way of phrasing it https://www.philipzucker.com/union-find-dict/
Edges can also be annotated. If the annotations form a group, that helps because you need to sometimes invert the annotations / have a null annotation. https://www.philipzucker.com/union-find-groupoid/
I’m neither convinced nor unconvinced requiring edge annotations be groups is the sweet spot.
I have some interesting examples I think where it is not a group, but some light asymmetry can be supported via the annotation forcing the parent / requiring a makeset https://www.philipzucker.com/thin_monus_uf/
As a reminder, here is what a basic offset union find looks like.
from dataclasses import dataclass, field
type FatId = tuple[int, int] # offset and id
@dataclass
class OffsetUF:
parents : list[FatId] = field(default_factory=list)
def makeset(self) -> FatId:
i = len(self.parents)
self.parents.append((0,i))
return (0,i)
def find(self, x : FatId) -> FatId:
off, xid = x
while True:
(offy, yid) = self.parents[xid]
if yid == xid:
assert offy == 0
return (off, xid)
off += offy
xid = yid
def union(self, x : FatId, y : FatId) -> FatId | None:
(offx, xid) = self.find(x)
(offy, yid) = self.find(y)
if xid != yid:
z = (offy - offx, yid)
self.parents[xid] = z
return z
else:
return None
def add(off, x : FatId) -> FatId:
return (off + x[0], x[1])
uf = OffsetUF()
x = uf.makeset()
y = uf.makeset()
uf.union(add(3, x), add(4, y))
uf
OffsetUF(parents=[(1, 1), (0, 1)])
The edge and root annotations can interact. If you have an offset and an even/odd/unknown analysis, of course x = y (+1) and even(x) implies odd(y). If you want to pull the annotation pack to a child from the root, or reroot, you need to know the group action on the annotation. Sometimes an edge annotation might transfer info into the lattice. Rudi is the one who taught me this. See the extended real offset union find below the fold for an example.
Looking back at Ed Kmett’s Guanxi talks https://youtu.be/ISNYPKiE0YU?si=Naz0It2sQwljIY_M https://github.com/ekmett/guanxi/blob/master/src/Relative/Internal.hs , he does talk about transporting his lattice like analysis via the group union find annotations. He also in his monoidal parsing talks refers to using group annotations as a way to lazily shift an entire structure of offsets. I think this is less in the tradition of the group union find and more in the tradition of semi-persistent data structures.
Semi-persistence
Semi-persistent data structures differ from persistent data structures in that you mutate under the hood and maybe the older copies are degraded in performance or capability in some way, but not gone.
In order to backtrack any data structure or state, you need to somehow keep a record of how to undo the moves you’ve done. This record may sometimes be implicitly on your language’s stack, but it is still there. What this amounts to is a chain of update structs linking up to the current mutated version. Instead of sort of being splayed out over all your code, it is possible to capture this up into a data structure that controls the most current mutated version and offers keys to the previous versions.
- https://inria.hal.science/hal-04045849v1/document Semi-persistent Data Structures Sylvain Conchon, Jean-Christophe Filliâtre, https://usr.lmf.cnrs.fr/~jcf/publis/puf-wml07.pdf A Persistent Union-Find Data Structure
- https://xavierleroy.org/CdF/2022-2023/ Leroy knocks it out of the park again
- https://github.com/yaspar-org/semi-persistent Interesting talk at EGRAPHS 2026 about semi persistent tecniques in this egraph and other things
- Interestingly, the rerooting technique seems like it goes back to at least a technique for shallow binding in lisp 1.5 https://web.archive.org/web/20191008134617/http://home.pipeline.com/~hbaker1/ShallowArrays.html https://web.archive.org/web/20200212080133/http://home.pipeline.com/~hbaker1/
As always, there is both an arena style and pointer style presentation. For some reason, I find arenas clearer.
from dataclasses import dataclass, field
# arena style version
type Id = int
@dataclass
class Arrayena:
data : list[object]
diff : list[tuple[int,object,Id] | None]
def __init__(self, size : int, default=None):
self.data = [default] * size
self.diff = [None]
def get(self, id : Id, idx : int) -> object:
# can path compress if we have dict of changes at each next
while self.diff[id] is not None:
idx1, data, id1 = self.diff[id]
if idx1 == idx:
return data
id = id1
return self.data[idx]
def reroot(self, id : Id):
if self.is_root(id):
return
else:
idx,v,id1 = self.diff[id]
self.reroot(id1)
self.diff[id1] = (idx, self.data[idx], id)
self.data[idx] = v
self.diff[id] = None
"""
# We could convert recusrive form into loops. I don't have this right here.
chain = []
self.diff[id] = None
while self.diff[id] is not None:
chain.append(id)
_, _, id = self.diff[id]
while len(chain) > 1: # reverse the chain
id = chain.pop()
idx, v, id1 = self.diff[id]
old_v = self.data[idx]
self.data[idx] = v
self.diff[id] = (idx, old_v, chain[-1])
"""
def is_root(self, id : Id) -> bool:
return self.diff[id] is None
def set(self, id : Id, idx : int, data : object) -> Id:
# but we could also do the non rerooting version.
self.reroot(id)
newid = len(self.diff)
self.diff.append(None)
self.diff[id] = (idx, self.data[idx], newid)
self.data[idx] = data
return newid
ID0 = 0
a = Arrayena(10, default="fred")
id1 = a.set(ID0, 3, "a")
a
assert a.get(id1, 3) == "a"
assert a.get(ID0, 3) == "fred"
assert a.is_root(id1)
assert not a.is_root(ID0)
a.reroot(ID0)
assert a.get(id1, 3) == "a"
assert a.get(ID0, 3) == "fred"
assert not a.is_root(id1)
assert a.is_root(ID0)
id2 = a.set(id1, 4, "b")
assert a.get(id2, 3) == "a"
assert a.get(id2, 4) == "b"
assert a.get(id1, 4) == "fred"
assert a.get(ID0, 3) == "fred"
a
Arrayena(data=['fred', 'fred', 'fred', 'a', 'b', 'fred', 'fred', 'fred', 'fred', 'fred'], diff=[(3, 'fred', 1), (4, 'fred', 2), None])
Theory of Arrays Union Find
This is a union find that has store held on the edges and a currently known mappings held at the root position. By using a rerooting technique very similar to the semi-persistent one, I believe we can support these non invertible edge annotations.
Similar to how the group union find needs the group elements to be concrete constants (like +42), the keys we update or assert at need to be concrete. This is a less powerful thing than the full SMT theory of arrays https://microsoft.github.io/z3guide/docs/theories/Arrays/ , since it makes determining aliasing (disequality) of keys trivial. But trivial is good. We are looking for very efficiently implementable and controllable subsets of capabilities.
Note that the smt theory of “arrays” is really a theory of functions / maps that so happens to be useful for modeling arrays. This nomenclature comes from the McCarthy theory of arrays.
Not Just A Semi-Persistent Array Union Find
There is a confusion of layers here I want to warn against. In the persistent union find paper https://usr.lmf.cnrs.fr/~jcf/publis/puf-wml07.pdf they are using this technique to make a regular union find that is persistent.
I AM DOING SOMETHING DIFFERENT.
What I am dicussing now is very similar in internals but instead is a mutated union find that supports a theory of arrays internally. The “difference” annotations from the semi-persistent structure go in the same place as group annotations and the “data” field goes roughly in the place of the lattice analysis of a union find.
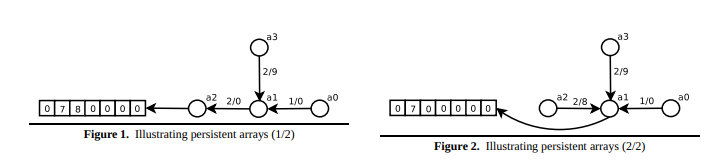
This is inspired by the semi-persistent array. Look again at the picture. Those chains are upward pointing trees. Union finds themselves are upward pointing trees / forests. I would draw a very similar picture for a group-lattice annnotated union find!!
One could also use the semi-persistent array technique on top of these structures to make a semi persistent version of the theory of arrays union find. That kind of the same structure is both outside and inside the thing is brain tickling in that strange loop kind of way.
What this thing supports is the creation of an abstract mapping we know nothing about and slowly refine our understanding of it via union assertions. Lazily we can make identifiers that represent elements at key k. Sometimes calling get calls makeset under the hood.
To make things simple (?) everything inside this union find represents a mapping. In that manner, the thing is reminiscent of hereditarily finite sets https://www.philipzucker.com/finiteset/ https://lawrencecpaulson.github.io/2022/02/23/Hereditarily_Finite.html , instead it kind of represents maps of maps of maps…. I suppose by another definition of simplicity maybe I should have had two sorts, maps and the things in the range of the maps.
It ain’t perfect. I think you could allocate less / makeset less / call find less. It also might be buggy. Still, I do believe it is possible to have this “update” theory baked into the union find.
type Id = int
# fatid is a dict of updates paired with a regular int id.
# in terms of smt style store the fat id `({k1:v1, k2:v2, k3:v3},int_id)` kind of
# represents a store chain `store(store(store(int_id, k1, v1), k2, v2), k3,v3)``
type FatId = tuple[dict[int, FatId], Id]
@dataclass
class ArrayUf: # "array" as in the theory of arrays
parents : list[FatId] = field(default_factory=list)
lattice : list[dict[int, FatId]] = field(default_factory=list)
def makeset(self):
id = len(self.parents)
self.parents.append(({}, id)) # empty dict is identity update
self.lattice.append({})
return ({}, id)
def find(self, id : FatId) -> FatId:
stores, id = id
while True:
stores1, id1 = self.parents[id]
stores = {**stores1, **stores}
# earlier stores override later stores. This is update composition.
# we need keys to be concrete entities to know how to resolve aliasing
if id1 == id:
# normalize stores to remove redundant entries
# This is kind of like how G is only meaningful wrt self symmettry closure?
lat = self.lattice[id]
# There might be a way to avoid
stores = {k : self.find(v) for k,v in stores.items() if self.select(({}, id), k) != self.find(v)} #k in lat and self.find(lat[k]) != self.find(v)}
return stores, id
id = id1
def select(self, id : FatId, index : int) -> FatId:
# get an identifier representing select(id, index) the element held at index position
stores, id = self.find(id)
if index in stores: # in store chain
return self.find(stores[index])
else:
v = self.lattice[id].get(index)
if v is not None: # in lattice
return self.find(v)
else: # we need to lazily makeset to give this entry an identifier
v = self.makeset()
self.lattice[id][index] = v
return v
def reroot(self, id : FatId) -> Id:
# just reroot by reifying the store chain as an id.
# a rerooting akin to the semi-persistent union find is probably also possible.
stores, id = self.find(id)
if len(stores) == 0: #all(self.lattice[id].get(k) == v for k,v in stores.items()): # if all stores a redundant
return id
else:
_, new_id = self.makeset() # TODO optimization: don't need to makeset if id0 was {} before find. We already have one then.
old_lat = self.lattice[id]
new_lattice = {**old_lat, **stores}
#new_diff = {k: old_lat[k] for k,v in new_lattice.items() if v != old_lat.get(k)} # could avoid unchanged stuff
new_diff = {k: self.select(({}, id), k) for k,v in new_lattice.items() if v != self.select(({}, id), k)}
self.lattice[new_id] = new_lattice
self.parents[id] = (new_diff, new_id)
self.lattice[id] = None # clear out old lattice. Shouldn't be accessed
return new_id
def union(self, id1 : FatId, id2 : FatId):
#print("union", id1, id2)
id1,id2 = self.find(id1), self.find(id2)
#
#print("union", id1, id2)
if id1 == id2:
return
elif id1[1] == id2[1]:
# same id but different stores. self symmettry
for k,v in id1[0].items():
self.union(v, self.select(id2, k))
for k,v in id2[0].items():
self.union(v, self.select(id1, k))
else:
#a = self.reroot(id0)
#bstore, b = id1
a,b = self.reroot(id1), self.reroot(id2) # probably don't need double reroot. Just reroot a, but then also need to merge from b[0]
alat, blat = self.lattice[a], self.lattice[b]
for i,v in alat.items():
self.union(self.select(id2, i), v)
#for k,v in bstore.items():
for i,v in self.lattice[b].items():
if i in alat:
self.union(v, alat[i])
self.parents[a] = ({}, b) # If I move this up, I might avoid infinite loop on non well founded union
self.lattice[a] = None
#self.lattice[b] = {**alat, **blat} # merge lattices.
def is_eq(self, x : FatId, y : FatId) -> bool:
return self.find(x) == self.find(y)
#analog of offset / act. store produces a _new_ object that has the value value at index.
# This is _not_"mutational/refining" store. That is done via `union(select(id, index), value)``
def store(id : FatId, index : int, value : FatId) -> FatId:
stores, id = id
stores = {**stores, index: value}
return (stores, id)
uf = ArrayUf()
x,y,z = [uf.makeset() for _ in range(3)]
x0 = uf.select(x, 0)
uf.union(x0, z)
assert uf.is_eq(x0, z)
assert uf.is_eq(uf.select(x, 0), z)
uf.union(x,y)
assert uf.is_eq(uf.select(y, 0), z)
assert uf.is_eq(uf.select(store(y, 1, z), 1), z)
uf.union(store(y, 1, z), y)
assert uf.is_eq(uf.select(y, 1), z)
assert uf.is_eq(uf.select(x, 1), z)
uf = ArrayUf()
a,b,x = [uf.makeset() for _ in range(3)]
uf.union(a, b)
assert uf.is_eq(a, b)
assert uf.is_eq(store(x, 0, a), store(x, 0, b))
uf = ArrayUf()
x,y,a,b = [uf.makeset() for _ in range(4)]
uf.union(store(x, 0, a), store(y, 0, b))
assert uf.is_eq(a, b)
uf = ArrayUf()
x = uf.makeset()
uf.union(store(x, 0, x), x)
assert uf.is_eq(uf.select(x, 0), x)
Bonus: Offset Union Find for Extended Reals
The extended reals https://en.wikipedia.org/wiki/Extended_real_number_line are a legitimate extension to the real numbers that is useful sometimes for making definitions of limits, supremum etc nicer.
Taking this as our intended semantic domain shows a nice example of the phenomenon of “self symmettries” in a group union find, where x = g + x for non trivial g. This occurs in the slotted union find and in the multiplication union find (0*x = x implies x = 0) but it’s a nice example of the phenomenon in the offset union find where it doesn’t imply an inconsistency.
x = 3 + x just means that x must be +-inf.
This example also helps distinguish that the group offset and the thing it’s being applied to don’t have the same type. Addition in the extended reals is not a group. act : Real -> EReal -> EReal
If you have a group action that you’re a fixed point of, that has something to do with stabilizers. https://en.wikipedia.org/wiki/Group_action#Orbits_and_stabilizers . One learns that you must be in one of the fixed point action sets of the group.
from enum import Enum
from dataclasses import dataclass, field
isinf = Enum('isinf', 'inf neginf fin') # or constant is nice too
type FatId = tuple[int, int]
@dataclass
class InfUf:
parents : list[FatId] = field(default_factory=list)
lattice : list[set[isinf]] = field(default_factory=list)
def find(self, x : FatId) -> FatId:
offset, id = x
while True:
offset2, id2 = self.parents[id]
offset += offset2
if id == id2:
return (offset, id)
id = id2
def union(self, x : FatId, y : FatId) -> None:
offsetx, idx = self.find(x)
offsety, idy = self.find(y)
if idx == idy:
if offsetx != offsety:
# if we have m + x = n + x, x can't be finite
self.lattice[idx] -= {isinf.fin}
return
self.parents[idx] = (offsety - offsetx, idy)
self.lattice[idy] &= self.lattice[idx]
assert len(self.lattice[idy]) != 0
def makeset(self):
id = len(self.parents)
self.parents.append((0, id))
self.lattice.append({isinf.inf, isinf.neginf, isinf.fin})
return (0, id)
def add(x : FatId, off : int) -> FatId:
offset, id = x
return (offset + off, id)
uf = InfUf()
x,y,z = [uf.makeset() for _ in range(3)]
uf.union(add(x, 1), add(y, 2))
assert uf.find(x) == (1,1)
uf.union(add(x,1), x)
uf.lattice
Bits and Bobbles
The presentation here might have been nicer if I had made a semi-persistent hashmap in the second section rather than array.
It was so hot today. 97F. Not perhaps the best day to debug a confusing piece of code. I was really thrashing until all the asserts stoped failing and I said fuck it. Ship it.
I haven’t posted in a while (June 1. A month. No sin. There is no such thing as sin if you’re not hurtin no one.). A lot of my attention went to getting my talk together for EGRAPHS 2026. And then I found myself super burnt out afterwards. But things picked up this week a little. Computers are no longer entirely loathesome to me. I think blogging is good. Gets my name out there. Gets conversations started. Gives me notes to refer back to. I debate whether I should blog more of less. It gets to be kind of stressful to stick to a deadline every week. On the other hand, there is no dearth of little ideas I haven’t written about. On the other hand, maybe everything I do is too incremental / non canonical? Dunno.
It does seem like versioned egraphs can be thought of as EMT’ed assume nodes like Rusell said. It is a bit different I think, because the union find needs to represent rules of the form assume(p, e_1) -> assume(p, e_2) where usually in the group union find it represents rules that are bare on the left hand side `e_1 -> act_g(e_2)$
The notion of a “first class union find” isn’t something I’ve chased in a while, but this internalized theory of arrays might be the right thing for it.
Semi-persistence is also very interesting in it’s relation to proof terms. If one did destructive rewriting semi persistently, the “diff” trail is surely (exactly?) some kind of proof term which is neato.
One could not have FatId that are full update dictionaries, but this is the form that allows path compression. It’s a tradeoff and it felt simpler to just do it the way I did it.
I was reading about bauer’s algebraic effects again https://arxiv.org/abs/1807.05923 . Is what I’m doing about algebraic effects? Store is an effect, but so is Print. Should print go on the union find edge? The parametrized term idea reminds me of the requirement that the storage location needs to be concrete.
Terms with arity 1000000000000000. Use compressed tries (bdd ish) for children
Is thi heridtary
https://github.com/yjs/yjs and automerge also had some stuff that kinda reminds me of Kmett’s monoidal diffs. They store diffs and communicate them and algerbaically combine them. Relationship to semi-persistence? CRDTs are like latticy though?
- https://www.philipzucker.com/union-find-groupoid/
- https://byorgey.github.io/blog/posts/2024/11/02/UnionFind.html https://byorgey.github.io/blog/posts/2024/11/18/UnionFind-sols.html
- https://dl.acm.org/doi/10.1145/3729298 Relational Abstractions Based on Labeled Union-Find
- https://exia.informatik.uni-ulm.de/fruehwirth/constraint-handling-rules-book.html Chapter 10
- https://leodemoura.github.io/files/oregon08.pdf Slide 167
- Sofia B pointed out https://link.springer.com/chapter/10.1007/978-3-540-39813-4_5 Congruence Closure with Integer Offsets
Normalization by evaluation. Lift Terms.
store(a, 1, 2) = b unstore(b, 1, a) = a
cas(a, 1, old, new) = b store takes in the value a currently has. permute them cas(b, 1, new, old) = a
Gvars
m?z?z = q is not necessarily easy Will this ever occur Two linear equations solve into a single nonlinear one. Even isolating in general is not easy ?z = p?q ?z = s?q
off(?z, off(?q, ?x))
Is it ok to just say z is solve and q = id?
Is it ok to just disallow compound patterns?
Don’t allow nonlinear patterns? But we want that for push up rules as rule
f([?z] * ?x, [?z] * ?y) = [?z]*f(?x, ?y)
identity is a solution. Everything is a solution? We can always pull out everything. We don’t insist that x and y stay bare… No, maybe we do?
f([?z] * ?x, [?z*?q] * ?y) = [?z]*f([id] * ?x, [q] * ?y)
We definitely need a the ability to factor
kind of / exactly a shostak api solve(systeqs) -> solved form
p =?z
?p = ?z*?q
?z = ?p*(?q)^-1 ?q free
Proof Terms
but not the proof terms you’re thinking of
It’s kind of a persistent data structure form of term. You do destrictvely rewrite, but retain a trail of undo steps.
https://en.wikipedia.org/wiki/Persistent_data_structure
Is Cong special or just another PTerm? It could have been rewritten itself
Smart constructors. Do they record what they’ve done or not?
Does cong pull?
https://inria.hal.science/hal-04045849v1/document semi persistentent “rerooting” storing diffs was what got kmett kind of excited about the group union find
https://www.cs.cmu.edu/~sleator/papers/another-persistence.pdf hmm. fat nodes with version stamps. Versioned egraph?
https://xavierleroy.org/CdF/2022-2023/ wow leroy has a whole course on them?
A term with a parray for children kind of ought to do it?
Arena style parray vs
Baker style
Persitetent array style idff relations in the union find. Then I don’t have to orient to prefix ordering
[a,b,c] + x = y x —–> drop(3, y) [p,q,r] + x = z
z —> modify([p,q,r], y)
It is invertible if you have an analysis on y saying what pieces you know about y.
modify = append(, drop( ))
Persistent Union find as a proof producing union find. We can store the old uncompressed version using persistence techniques. but we might like boosting the diff trail with extra explain data.
https://github.com/yaspar-org/semi-persistent
The locations can’t go away when you fill them.
from dataclasses import dataclass, field
# arena style version
"""
# multiple diff types
@dataclass(frozen=True)
class Store:
k : object
v : object
next : Id
@dataclass(frozen=True)
class Delete:
k : object
next : Id
type Diff = Store | Delete
# Algebraic effects?
"""
type Id = int
@dataclass
class Dictena:
data : dict[object, object]
diff : list[tuple[int,object,Id] | None]
def __init__(self, size, default=None):
self.data = [default] * size
self.diff = [None]
def get(self, id, idx : int):
# can path compress if we have dict of changes at each next
while self.diff[id] is not None:
idx1, data, id1 = self.diff[id]
if idx1 == idx:
return data
id = id1
return self.data[idx]
def reroot(self, id) -> id:
if self.diff[id] is None:
return
else:
idx,v,id1 = self.diff[id]
self.reroot(id1)
self.diff[id1] = (idx, self.data[idx], id)
self.data[idx] = v
"""
# We could convert recusrive form into loops. I don't have this right here.
chain = []
self.diff[id] = None
while self.diff[id] is not None:
chain.append(id)
_, _, id = self.diff[id]
while len(chain) > 1: # reverse the chain
id = chain.pop()
idx, v, id1 = self.diff[id]
old_v = self.data[idx]
self.data[idx] = v
self.diff[id] = (idx, old_v, chain[-1])
"""
def set(self, id, idx : int, data : object) -> id:
# but we could also do the non rerooting version.
self.reroot(id)
newid = len(self.diff)
self.diff.append(None)
self.diff[id] = (idx, self.data[idx], newid)
self.data[idx] = data
return newid
ID0 = 0
a = Arrayena(10, default="fred")
id1 = a.set(ID0, 3, "a")
a
assert a.get(id1, 3) == "a"
assert a.get(ID0, 3) == "fred"
[{<isinf.fin: 3>, <isinf.inf: 1>, <isinf.neginf: 2>},
{<isinf.inf: 1>, <isinf.neginf: 2>},
{<isinf.fin: 3>, <isinf.inf: 1>, <isinf.neginf: 2>}]
Arrays of arrays of arrays … All open ended on their size. The smt theory of arrays with ground index labels. Kind of is evocative of store algerbaic effect?
Theory of Arrays (ToA) Union Find
This is another generalized union find that isn’t invertible persay. Quite non invertible
It is directly inspired by the rerooting methodology as found in semi persistent data structures. There is a confusion of mental layers here because the semi persistent array is discussed in the context of being used to build a semi persistent ordinary union find.
A difference of this “theory of arrays” and that in the SMT version is that the addresses must be ground / equality and disequality are immediately determimable. This makes the problem much easier, since aliasing of keys can be immediately determined.
This is in analogy to the group union find which allows ground group element annotations. Because we insist on that groundness, the whole thing feels a little bit like some kind of generalized constant propagation. But the whole game we’re playing is trying to define highly tractable chunks of reasoning (questions about relationships being answerable in linearish or sublinearish time and also not much space like in a basic union find). Being underwhelming is kind of the point.
type Id = int
type FatId = tuple[dict[int, FatId], Id] # concrete integers to
@dataclass
class ArrayUf: # as in the theory of arrays
parents : list[FatId] = field(default_factory=list)
lattice : list[dict[int, FatId]] = field(default_factory=list)
def makeset(self):
id = len(self.parents)
self.parents.append(({}, id))
self.lattice.append({})
return ({}, id)
def find(self, id : FatId) -> FatId:
stores, id = id
while True:
stores1, id1 = self.parents[id]
stores = {**stores1, **stores} # earlier overide later stores
if id1 == id:
return stores, id
id = id1
def get_value(self, id : FatId, index : int) -> FatId:
stores, id = self.find(id)
if index in stores:
return stores[index]
else:
v = self.lattice[id].get(index)
if v is not None:
return v
else:
v = self.makeset()
self.lattice[id][index] = v
return v
def reroot(self, id : FatId) -> Id:
stores, id = self.find(id)
if all(self.lattice[id].get(k) == v for k,v in stores.items()):
return id
else:
_, new_id = self.makeset() # don't need to makeset if id0 was {} before find. We already have one then.
old_lat = self.lattice[id]
new_lattice = {**old_lat, **stores}
new_store = {k: old_lat[k] for k,v in new_lattice.items() if v != old_lat.get(k)} # could avoid unchanged stuff
self.lattice[new_id] = new_lattice
self.parents[id] = (new_store, new_id)
return new_id
def union(self, id1 : FatId, id2 : FatId):
a,b = self.reroot(id1), self.reroot(id2) # don't need double reroot
if a == b:
return
else:
alat, blat = self.lattice[a], self.lattice[b]
for i,v in self.lattice[a].items():
if i in blat:
self.union(v, blat[i])
for i,v in self.lattice[b].items():
if i in alat:
self.union(v, alat[i])
self.parents[a] = ({}, b) # If I move this up, I might avoid infinite loop on non well founded union
"""
a,b = self.find(id1), self.find(id2) # reroot reroot?
for i,v in a[0].items():
self.union(self.get_value(b, i), i)
for i,v in self.lattice[a[1]].items():
self.union(self.get_value(b, i), i)
for i,v in b[0].items():
self.union(self.get_value(a, i), i)
for i,v in self.lattice[b[1]].items():
self.union(self.get_value(a, i), i)
"""
#analog of offset / act
def store(id : FatId, index : int, value : FatId) -> FatId:
stores, id = id
stores = {**stores, index: value}
return (stores, id)
uf = ArrayUf()
x,y,z = [uf.makeset() for _ in range(3)]
x0 = uf.get_value(x, 0)
uf.union(x0, z)
uf.union(x,y)
uf
ArrayUf(parents=[({}, 1), ({}, 1), ({}, 2), ({}, 2)], lattice=[{0: ({}, 3)}, {}, {}, {}])
def value_at(self, id : FatId, index : int, value : FatId):
# assert the value at index of the array represented by id is value
stores, id = self.find(id)
if index in stores:
self.union(stores[index], value)
else:
v = self.lattice[id].get(index)
if v is not None:
self.union(v, value)
else:
self.lattice[id][index] = value
from dataclasses import dataclass, field
type Id = int
type Value = str
@dataclass
class Insert:
idx : int | None
value : Value
#type FatId = tuple[list[Insert], Id]
type FatId = tuple[dict[int, str], Id]
def normalize(inserts : list[Insert]) -> list[Insert]:
inserts1 = []
for insert in inserts:
if insert.idx is not None:
inserts1.append(insert)
return inserts1
class ArrayUf:
parents : list[FatId]
analysis : list[list[Value | None]]
def makeset(self, size):
id = len(self.parents)
self.parents.append(([], id))
self.analysis = [[None] for _ in range(size)]
def find(self, id : FatId) -> FatId:
inserts, id = id
while True:
inserts1, id1 = self.parents[id]
inserts = inserts + inserts1
if id1 == id:
return (normalize(inserts), id)
id = id1
def reroot(self, id : FatId) -> Id: ...
def union(self, id1 : FatId, id2 : FatId) -> FatId:
# pointery version
class ArrayRef:
idx : int
data : object
next : PArray
class ArrayList:
data : list[object]
type PArray = ArrayRef | ArrayList
# arena style version
class Arrayena:
data : list[object]
next : list[tuple[int,object,int] | None]
def get(self, id, idx : int):
# can path compress if we have dict of changes at each next
while self.next[id] is not None:
idx1, data, id1 = self.next[id]
if idx1 == idx:
return data
id = id1
return self.data[idx]
def reroot(self, id) -> id:
chain = []
while self.next[id] is not None:
chain.append(id)
idx, data, id1 = self.next[id]
while chain:
id = chain.pop()
idx, data, id1 = self.next[id]
self.next[id] = (idx, data, id)
def set(self, id, idx : int, data : object) -> id:
# but we could also do the non rerooting version.
self.reroot(id)
newid = len(self.next)
self.next.append(None)
self.next[id] = (idx, data, newid)
return newid
class PArray:
data : list
trail :
def set(self, index, value):
self.trail.append((index, self.data[index]))
self.data[index] = value
def push():
def pop():
class PTerm: ...
type Comp = tuple[PTerm,...]
#class Refl(PStep): ...
# refl is []
#class RW(PStep):
# lhs : PTerm
# rhs : PTerm
# subst : dict[str, PTerm] # substitution
class RW(PStep):
lhs : PTerm # rhs is implicit from context?
explain : object # other data such as rule label.
class Cong(PStep):
f : str
args : list[Comp,...]
inv : bool # inversion
#trail : list[tuple[PTerm, PTerm]]
class App:
f : str
args : list[PTerm]
trail : Comp # composition chain
App("refl",[],[])
App("cong", [], [])
ematching as a kanren like flp
subst -> list subst is kanren. Shallow on the predicates
match_step
What I’m describing
FLP.
If I want to calculate fact(32) = ?a what is the top level goal?
from dataclasses import dataclass, field
class Term:
def __add__(self, other):
return App("+", [self, other])
@dataclass
class Var(Term):
name : str
@dataclass
class App(Term):
f : str
args : list[Term]
type Subst = dict[str, Term]
type State = tuple[Subst, list[tuple[Term, Term]]]
def run(t, pat):
branches = [({}, [])]
while branches:
subst, goals = branches.pop()
(t, pat) = goals.pop()
def group_match_step(subst, t, pat):
def fact_match_step(subst, t, pat):
if t.f == "fact":
t.args
else:
return None
solve : G -> G -> list G # g1(X) = g?(g2(X))
pull/canon : str -> list (G,Int) -> G, Node # f(g1(X),g2(Y)) = g3(f(X,Y))
push/unapply/children : G, Node -> list (G, Int) # g3(f(X,Y)) -> f(g1(X), g2(Y))
comp : G -> G -> G # g1(g2(X)) = g3(X)
id : dom -> G # X = id(X)
union : (G,Int) -> (G,Int) -> ??
process : (G, Int) -> (G, Int) -> list ((G, Int), (G,Int)) # kind of a unification move?
reflect : (G,Id) -> Node
reify : Node -> Option (G,Id)
A sketch of api functions and rule form of them. I am not convinced I have the right types in the right spots or right concepts in the right spotsPhilip Zucker: I guess solve is what I needed of inverse. There were multiple solutions and I could enumerate them in thinningsPhilip Zucker: solve showed up when i needed to match through data in the union find.Philip Zucker: union could perhaps return a processed pairs. There is also
Or vice versa on the names
Try to summarize for myself and others what we’ve been thinking about
Well, I have a ton of posts about variants of unions finds. I was even gonna maybe give an egraphs talk about them
Groups act on lattices. It’s actually natural
Groupoid vs group doesn’t seem that special. We can often widen our domain such that the partiality of the groupoid isn’t that important
| x, y, z | - t |
| x : a = b | - a = b |
| x : a = b | - t a function from the proof object of a = b to a term t? |
thinnings and colored
https://en.wikipedia.org/wiki/Modular_lattice https://en.wikipedia.org/wiki/Lattice_of_subgroups https://en.wikipedia.org/wiki/Isomorphism_theorems#Second_isomorphism_theorem
Tree like lattices? modular lattices? https://en.wikipedia.org/wiki/Semimodular_lattice matroids
matroids are linear spaces…
Versioned egraphs https://colab.research.google.com/drive/1rSgg13v9yKvtNQIsORHPSskKQFEj4g4s?usp=sharing
dict[Version, dict[Version, T]] -> dict[Version, T]
join : f f a -> f a unit : a -> f a
monad is model of substitution. Iterated subtitution is path compression. But union needs some oomph
dict[Version, Id] vs (G, Id)
G represents the coset by the symmettry subgroup https://en.wikipedia.org/wiki/Coset The symmettry subgroup has to be normal for path compression to make sense? Eh. I dunno about that.
are solve and unify_step the same?
versioning has ass(e) -> ass(e) in union find. But critical pairs can still be theory normalized
ass(e1) -> ass(e2) ->
solve g = ?k . l kind of finds crticial pairs between l and g annotions.
generalized ground knuth bendix
crit : G -> G -> list (Ctx, Ctx) # plug ctx1 g1 = plug ctx2 g2 plug : Ctx -> G -> G
ass_p ass_q —> q is sub p == version propagation step.
versions and assume nodes
assume(p, t) = ite(p, t, default) assume(not(p), t) = ite(p, default, t)
Put ordering on p0,p1,p2
versions are more than boolean assume(p, n, t) = ite(p == n, t, default)
eids as tries / bdds
union(x,y,v) = assume(v=True,x) == assume(v=True, y)
assume(v, assume(v2, t)) = assume(v, assume(v, t)) = assume(v,t) assume(v=True, assume(v=false, T)) = default
They are kind of functional objects just like bdds are
union(x,y,0.1.1)
q and p are assumption strings 0.1.2.2 $assume_q(assume_p(t)) = assume_{max(p,q)}(t)$ $assume_p(assume_(q)) = junk$ if p and q incompatible $f(assume_p(x), assume_p(y)) = assume_p(f(x,y))$
union(x,y,v) api assures we don’t equate unequal stuff.
[[assume_p(t)]] = fun x0,x1,x2,.. -> if x0=p0 /\ x1 = p1 /\ … then [t] else junk
Option form: fun x0,x1,x2,.. -> if … then [t] else None [[42]] = Some 42 [[t + s]] = [[assume(p, t)]] =
But were assumptions tagging in a contravaraint or covariant sense if that makes sense?
find(x,v) == find(assume_p(x))
global assumptions ordered c0,c1,c2,c3,…
fun conds ->
It is close to thinnings…
assume_p(t) = assume_q(s)
Yes, this is very similar to the https://arxiv.org/pdf/2303.01839 assume node paper’s semantics, but they tie in the value of the conditions and the variable values. Which you can kind of do via x == 3 in world a.
Hmm. Maybe the union find rewrite rules are of the form ass(e) -> e which is why there is some search for best match.
assume(v, t) = assume(v2, s) makes no sense it v != v2, because we’d be saying in some circumstances, s or t == junk… Well, maybe.
assume is more like dump than lift?
assume(c0, True) ~ reflected c0 assume(not(c0), False)
[[expr]] : Bool^n -> R (Option R) [[]]
assume([True, False], t) == assume([True, False], s) prefix ordering
assume([True, False], t)
allowing arbitrary expressions into assume nodes is like having an egraph reflected lattice or group rather than a baked in constant one
assume_d(e1) -> e7 assume_c(e1) -> e8
d and c can have overlap if one is prefix of the other. Otherwise we’re good.
I did believe at one point that theory combination with an unary symbol with a normalization algorithm (string). ought to work ok. A familiy of unary functions symbols f_i(e) = f_j(e)
def assume(n,i,t):
return lambda *cs: t(*cs) if c[n] == i else None
type FatId = (tuple[bool | None], int)
class Node
f : str
args : list[FatId]
type UF = list[FatId]
class UF:
#parents : list[FatId] #? but the versioned uf is splitting.
parents : list[list[FatId]] # find best
def find(self, x : FatId) -> FatId: # find(x, v) sure.
(ass, id) = x
#best_match(ass, self.parents[x]) #?
while True:
id3 = None
for (ass1, id2) in self.parents[id]:
if len(ass1) <= len(ass) and ass[:len(ass1)] == ass1:
ass = ass1
id3 = id2
if id3 is None:
return (ass, id)
"""
ass(v1, e1) -> e2
ass(v2, e1) -> e7
"""
def union(self, x : FatId, y : FatId) # can union(x,y,v)
assert x[0] == y[0] # better damn be compatible. Is relaxation to prefix compatbility possible?
x,y = self.find(x), self.find(y)
class Theory(Protocol):
def comp(a,b): ...
def id(): ...
def canon(): ...
def unapply(): ...
def reify(): ...
def reflect(): ...