PCode2C: Steps Towards Translation Validation with Ghidra and CBMC
Pcode2C is a translator from low pcode (Ghidra’s IR) to C for the purposes of running the resulting code through off the shelf C verifiers. Unlike typical decompilation, the resulting C has a direct mapping to the original assembly.
The code is here https://github.com/philzook58/pcode2c. It’s a work in progress.
C is a useful intermediate for binary analysis because it enables using powerful off the shelf verifiers, can be directly compared (with a little muscle grease) against decompilaton or source, and also can be directly compiled by gcc for fast interpretation / fuzzing.
C isn’t great because it’s a complicated mess. Undefined behavior, yada yada. We are trying to stick to the uncomplicated bits, and the complication is in ingesting it more than producing it, which is someone else’s problem. Hope springs eternal.
This tool enables soundly answering questions about the relationship between high level source and binary in a relatively easy manner that no other method I know of can do. This can be done by running the high level code and the binary lifted code in the same C program and write assertions about their relative executions.
It is also a method to ask questions about just the binary behavior (are there overflows? Termination? Etc). Building test/proof harnesses and assertions is done in normal C, so hopefully is more accessible to typical the low level wizard sensibilities. I have had a lot of trouble bridging the audiences.
Here’s how pcode2c works:
A small Ghidra python script dumps the pcode in C syntax. The printing is very direct.
Consider this toy example program that takes the minimum of two numbers
#include <stdint.h>
int64_t mymin(int64_t x, int64_t y)
{
return x < y ? x : y;
}
This compiles to this x86 assembly:
mymin.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <mymin>:
0: f3 0f 1e fa endbr64
4: 48 39 fe cmp %rdi,%rsi
7: 48 89 f8 mov %rdi,%rax
a: 48 0f 4e c6 cmovle %rsi,%rax
e: c3 ret
We open up Ghidra and click run in the toolbar.
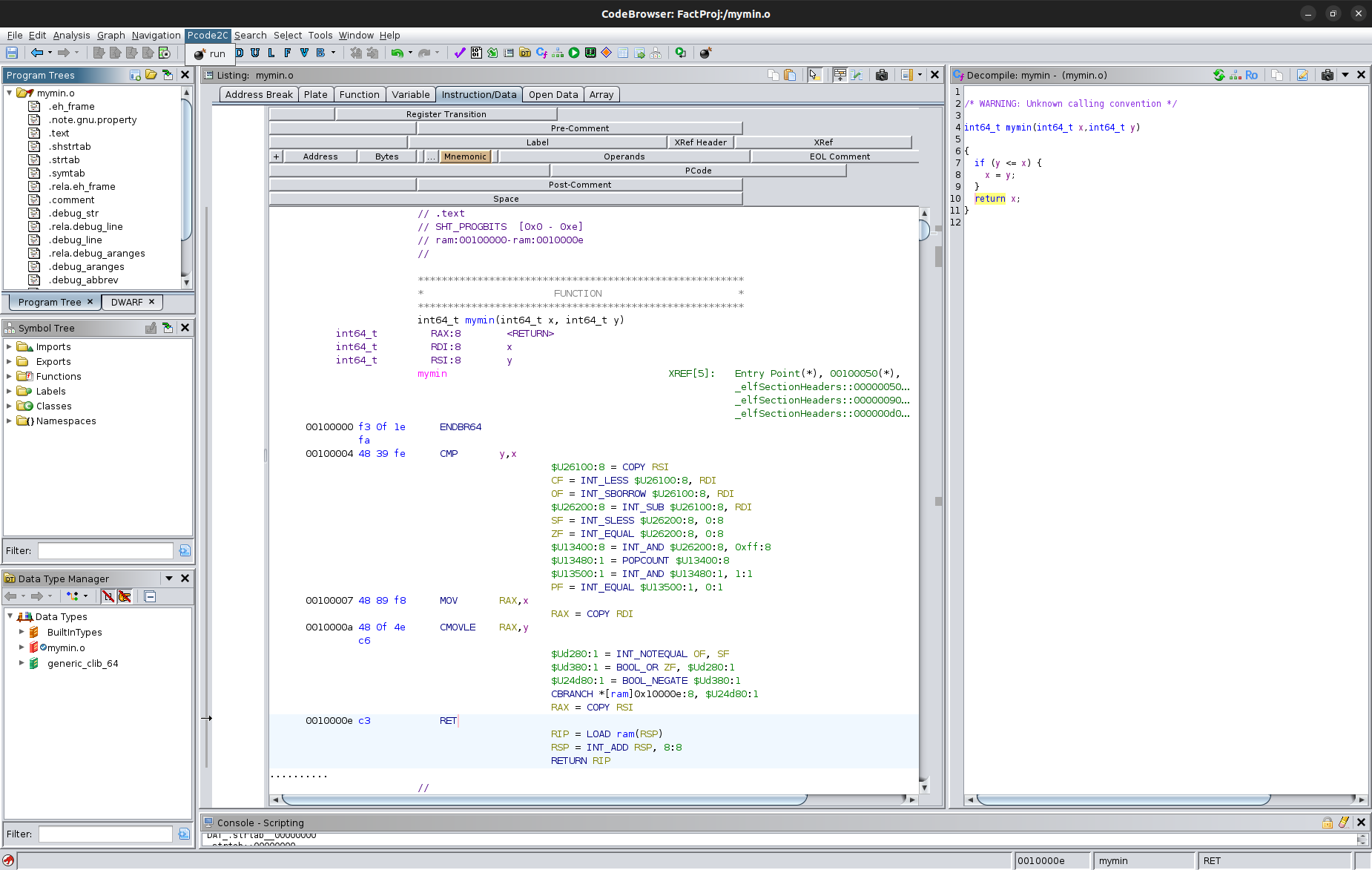
This following is the resulting file from pcode2c. Hopefully it is clear this is a direct translation from the Ghidra, and hence a direct translation back to the assembly.
/* AUTOGENERATED. DO NOT EDIT. */
#include "pcode.h"
void mymin(CPUState *state, size_t breakpoint)
{
uint8_t *reg = state->reg;
uint8_t *unique = state->unique;
uint8_t *ram = state->ram;
for (;;)
{
switch (state->pc)
{
case 0x00100000:
INSN(0x00100000, "ENDBR64")
case 0x00100004:
INSN(0x00100004, "CMP RSI,RDI")
COPY(unique + 0x26100, 8, reg + 0x30 /* RSI */, 8); // (unique, 0x26100, 8) COPY (register, 0x30, 8)
INT_LESS(reg + 0x200 /* CF */, 1, unique + 0x26100, 8, reg + 0x38 /* RDI */, 8); // (register, 0x200, 1) INT_LESS (unique, 0x26100, 8) , (register, 0x38, 8)
INT_SBORROW(reg + 0x20b /* OF */, 1, unique + 0x26100, 8, reg + 0x38 /* RDI */, 8); // (register, 0x20b, 1) INT_SBORROW (unique, 0x26100, 8) , (register, 0x38, 8)
INT_SUB(unique + 0x26200, 8, unique + 0x26100, 8, reg + 0x38 /* RDI */, 8); // (unique, 0x26200, 8) INT_SUB (unique, 0x26100, 8) , (register, 0x38, 8)
INT_SLESS(reg + 0x207 /* SF */, 1, unique + 0x26200, 8, &(int64_t){0x0L}, 8); // (register, 0x207, 1) INT_SLESS (unique, 0x26200, 8) , (const, 0x0, 8)
INT_EQUAL(reg + 0x206 /* ZF */, 1, unique + 0x26200, 8, &(int64_t){0x0L}, 8); // (register, 0x206, 1) INT_EQUAL (unique, 0x26200, 8) , (const, 0x0, 8)
INT_AND(unique + 0x13400, 8, unique + 0x26200, 8, &(int64_t){0xffL}, 8); // (unique, 0x13400, 8) INT_AND (unique, 0x26200, 8) , (const, 0xff, 8)
POPCOUNT(unique + 0x13480, 1, unique + 0x13400, 8); // (unique, 0x13480, 1) POPCOUNT (unique, 0x13400, 8)
INT_AND(unique + 0x13500, 1, unique + 0x13480, 1, &(int8_t){0x1L}, 1); // (unique, 0x13500, 1) INT_AND (unique, 0x13480, 1) , (const, 0x1, 1)
INT_EQUAL(reg + 0x202 /* PF */, 1, unique + 0x13500, 1, &(int8_t){0x0L}, 1); // (register, 0x202, 1) INT_EQUAL (unique, 0x13500, 1) , (const, 0x0, 1)
case 0x00100007:
INSN(0x00100007, "MOV RAX,RDI")
COPY(reg + 0x0 /* RAX */, 8, reg + 0x38 /* RDI */, 8); // (register, 0x0, 8) COPY (register, 0x38, 8)
case 0x0010000a:
INSN(0x0010000a, "CMOVLE RAX,RSI")
INT_NOTEQUAL(unique + 0xd280, 1, reg + 0x20b /* OF */, 1, reg + 0x207 /* SF */, 1); // (unique, 0xd280, 1) INT_NOTEQUAL (register, 0x20b, 1) , (register, 0x207, 1)
BOOL_OR(unique + 0xd380, 1, reg + 0x206 /* ZF */, 1, unique + 0xd280, 1); // (unique, 0xd380, 1) BOOL_OR (register, 0x206, 1) , (unique, 0xd280, 1)
BOOL_NEGATE(unique + 0x24d80, 1, unique + 0xd380, 1); // (unique, 0x24d80, 1) BOOL_NEGATE (unique, 0xd380, 1)
CBRANCH(ram + 0x10000e, 8, unique + 0x24d80, 1); // --- CBRANCH (ram, 0x10000e, 8) , (unique, 0x24d80, 1)
COPY(reg + 0x0 /* RAX */, 8, reg + 0x30 /* RSI */, 8); // (register, 0x0, 8) COPY (register, 0x30, 8)
case 0x0010000e:
INSN(0x0010000e, "RET")
LOAD(reg + 0x288 /* RIP */, 8, &(int64_t){0x1b1L}, 8, reg + 0x20 /* RSP */, 8); // (register, 0x288, 8) LOAD (const, 0x1b1, 8) , (register, 0x20, 8)
INT_ADD(reg + 0x20 /* RSP */, 8, reg + 0x20 /* RSP */, 8, &(int64_t){0x8L}, 8); // (register, 0x20, 8) INT_ADD (register, 0x20, 8) , (const, 0x8, 8)
RETURN(reg + 0x288 /* RIP */, 8); // --- RETURN (register, 0x288, 8)
default:
assert(0); // Unexpected Control Flow
}
}
}
The bulk of the work is writing all these helper functions and macros in the file pcode.h. At the moment it is incomplete, but I believe this is possible to do eventually even if I don’t have complete confidence quite yet.
It is however complete enough to both compile this program and run a property through the C bounded model checker CBMC. This tool symbolically executes the C program and checks assertions you write in the verification harness in addition to checking standard issues like overflow, memory safety, etc. An aside: CBMC and tools like it are radically underutilized. They are quite easy to use (very automatic) and catch problems for me all the time.
A harness has to be built to setup the state and check the property. A lot of this is the same template every time, but some isn’t.
#include "decomp.c"
#include "arch.h"
#include <stdio.h>
int main()
{
CPUState state;
uint8_t reg[0x300] = {0}; // actually using built in cbmc malloc is dramatically faster for some reason
uint8_t unique[0x261000];
uint8_t ram[1024] = {0};
state.reg = reg;
state.unique = unique;
state.ram = ram;
state.pc = 0x00100000;
uint8_t rsi, rdi; // yeah I'm cheating a little here.
// rsi = 3;
// rdi = 10;
state.reg[RSI] = rsi;
state.reg[RDI] = rdi;
mymin(&state, -1);
uint8_t ret = state.reg[RAX];
assert(ret == rsi || ret == rdi);
assert(ret <= rsi && ret <= rdi);
printf("pc: 0x%lx\n", state.pc);
printf("RAX: %d\n", state.reg[RAX]);
return 0;
}
Note that this is all perfectly valid C. gcc will accept it and you can fuzz the thing also for extra assurance / alternative pathways. The ability to run through gcc has been absolutely crucial for my debugging of the thing and pcode.h is sprinkled with judicious printf of instructions and cpu state.
$ cbmc harness.c --object-bits 10 --unwind 2 --property main.assertion.1 --property main.assertion.2 --unwinding-assertions --boolector
CBMC version 5.12 (cbmc-5.12) 64-bit x86_64 linux
Parsing harness.c
Converting
Type-checking harness
Generating GOTO Program
Adding CPROVER library (x86_64)
Removal of function pointers and virtual functions
Generic Property Instrumentation
Running with 10 object bits, 54 offset bits (user-specified)
Starting Bounded Model Checking
Unwinding loop mymin.0 iteration 1 file decomp.c line 5 function mymin thread 0
Not unwinding loop mymin.0 iteration 2 file decomp.c line 5 function mymin thread 0
size of program expression: 12608 steps
simple slicing removed 35 assignments
Generated 3 VCC(s), 3 remaining after simplification
Passing problem to SMT2 QF_AUFBV using Boolector
converting SSA
Running SMT2 QF_AUFBV using Boolector
Runtime decision procedure: 0.334741s
** Results:
decomp.c function mymin
[mymin.unwind.0] line 5 unwinding assertion loop 0: SUCCESS
harness.c function main
[main.assertion.1] line 22 assertion ret == rsi || ret == rdi: SUCCESS
[main.assertion.2] line 23 assertion ret <= rsi && ret <= rdi: SUCCESS
** 0 of 3 failed (1 iterations)
VERIFICATION SUCCESSFUL
That’s the gist and all the rest of this post is just wandering commentary.
Bits and Bobbles
TODO
There’s a lot of place to go with this. I think it’s an exciting approach.
- Still need more completeness and correctness. I’m sure I’m not handling all the cases correctly.
- Command line version using angr’s pypcode. I like angr’s installation story and sometimes I like just using the command line and not opening ghidra.
- Fuzzing.
- Trying other backends besides CBMC
- Extracting Invariants from cpachecker / uautomizer
- Termination certificates?
- Comparative verification against C source. There’s a fun ping ponging trick.
- Examine the GOTO output and try to emit constructs that are verifier friendly.
- Maybe some smarts should happen in the printer. Unpack registers? Make temps for uniques? I don’t know what matters for verifier speed. I tried to be as direct as possible Other interesting approaches include dumping Dafny or WhyML or MLCFG or lean version or what have you. These don’t make comparison to decompilation or source easy, nor are they going to be accessible to a typical reverse engineer / low level hacker.
- Arduino code? eBPF? Ghidra supports both.
- A Formal Semantics for P-Code https://github.com/niconaus/pcode-interpreter https://github.com/niconaus/PCode-Dump Related but distinct approach.
PCode2C as Partial Evaluation of an Interpreter
It is possible (and ghidra includes one) to write an interpreter for pcode. We can choose to write this interpreter in C.
A simplistic version of this interpreter would look something like this:
typedef enum {INT_ADD, INT_SUB, ...} opcode_t;
typedef struct {
enum Opcode opcode;
Varnode arg[4];
} instruction_t;
typedef struct {
uint8_t reg[0x5000];
uint64_t pc;
uint8_t mem[x1000000];
} CPUState;
instruction_t insns[0x1000000]; // and initialize it somewhere
void interp(CPUState *state){
for(;;){
insn = insns[state.pc];
switch(insn.opcode) {
case INT_ADD:
// Actually more complicated because varnodes are of various sizes, casting, etc.
state.reg[insn.arg[0].offset] = state.reg[insn.arg[1].offset] + state.reg[insn.arg[2].offset];
state.pc += 1;
break;
case INT_SUB:
...
}
}
}
An interpreter of this kind is a function interp : [Insn] -> CPUState -> CPUState. But we have a specific program we’re looking at, so we could partially apply this function special_interp : CPUState -> CPUState = interp myprog. This is known as a Futamura projection. It is possible to do this interpreter specialization actually rather than spiritually in languages like Lisp or MetaOcaml, but C isn’t the greatest language for that, so I just pretty print a reasonable specialization.
One reason to do this is to make it easier to edit the file and add custom instrumentation and annotations after the fact. Another reason is that we can avoid a lot of dispatching back to the top of the loop, since it is quite obvious statically that many instructions fall through. This helps bounded model checking, as we only need to unroll blocks instead of each instruction. These are not strong reasons and a reasonable design may be just to go back to the interpreter form.
Why Binary Verification?
Binaries are a thin pipe. There is a huge pile of hardware stuff underneath, and a tremendous topling tower of languages and software above.
There is a long history of wanting to translate binaries from one ISA to another (see Cifuentes thesis). There are an number of approaches. Really, one wants to work in a portable higher level language in the first place. This is not always a silver bullet.
There are a number of reasons to perform binary translation.
Why do we want to verify at the binary level
- High Low Correspondence Recovery. Optimizing compiler by design mangle your code as much as is fruitful during the translation to assembly. This makes the correspondence of CPU state and high level state difficult to pin down except at agreed locations such as function entry and exit (These sorts of things are referred to as the ABI). The interior of functions is often a bit vague exactly how the high code corresponds to the low code. This information is possibly usefl for a couple use cases.
- Smaller verification chunks / more verification targets
- Better Debug Data
- Post Hoc Patchability (microlinking). In principle one could seriously reduce compile times. Similar to how separate compilation and linking allows one to limit the amount of recompilation one has to do. One ould imagine microlinking or dynamic microlinking/patching.
- More precise decompilation
If you need to connect the hgh code to the low code, you need them to somehow be in the same system.
- Compiler Validation.
- Decompiler Validation
- Binary Verification
There are more frameworks for higher level language verification. The options for assembly are more limited.
Interpret, JIT, or Decompile
In principle, writing an interpreter for assembly is laborious but straightforward. You can for example find many smple emulators on the internet for gameboys. A straight interpreter is perceived as being too slow for many applications. Another approach that has been sucessful is dynamic binary translation like QEMU. In this case, the recovery of control flow is done by executing the program and having a fast JIT engine to translate to the host arhchitecture.
The basic state of a CPU is the value in it’s registers (including the program counter), and the values in memory. You can make a data structure representing this. Then some kind of looping dispatch (while + switch) on the current address pointed to PC and do the operations that instruction specifies.
We can specialize this interpreter to a particular sequence of instructions. We don’t need to necessarily dispatch back to the switch statement if we statically know where execution will go next.
Typical decompilation takes a further step of noting that lots of things the cpu is doing are statically recognizable as unnecessary and control flow can be simplified further.
Decompilers are a known entity and very useful for human reverse engineers to naviagte their way around a binary.
Decompilation can be perceived as trying to recover something similar to the original source.
Recompilable decompilation is decompilation that can be thrown into gcc and produce a new binary. This sounds great, but is very challenging.
Why C?
There are a couple of advantages of using C as an IR to verifiers.
- Lots of work has been invested. Can use preeexistig verifiers, linters, knwon problems.
- It can be compiled and run. Fuzzing can be a good sanity check that all tghe pieces are working as expected.
- It is comprehensible and familiar to engineers. Building a new language is a lot of work and learning this language is also. Most languages fail.
C is of course not ideal in that it has some peculair semantics. Some of this is historical baggage, some is defined to enable compiler optimizations, which is not useful here. The semantics of an add instruction are not up for as much debate as the semantics of the C addition operator. The processor does something when an integer overflows. In C, what “happens” on overflow is more subtle.
In any case it is worth a shot.
Off the shelf C automated verification is underutilized. It is quite nice and very powerful.
Is Verification Worthwhile?
No. This is why software verification is kind of a backwater. It delivers second or third order value. Compilers are intended to produce correct code. They are imperfect, fine. So is the world. How Badly Do We Want Correct Compilers? - John Regehr
But it is kind of a fun.
What is good? Happiness, lives, and money. In the sense the subject is intrinsically beuatiful it increases happiness. Money in the software world translates to requiring fewer or cheaper salaries, or less bugs for which you are financially liable. Ransomware. For very expensive physical systems, making sure they don’t blow up because of some dumb bug is good
Lives is worrying. This is the critical systems (planes, rockets, automated vehicles) or defense or medical devices.
Probably the most value is not the verification persay, but having someone smart enough to do something akin to verification pour over your system.
Having said that, testing is good because it is an automatic form of sanity checking. mployees come and go and we all oly have so much brain space or attention span.
Why Ghidra?
Ghidra is a remarkable entity. It is a decompiler with around 20 years of history and government funding by the NSA. It is not going anywhere.
PCode is ghidra’s intermediate representation. It is a smaller target than QEMU or VEX, which are designed for dynamic binary translation. They have more constructs in their IR in order to support more efficient translations. Whereas PCode’s main purpose is static analysis/decompilation, not necessarily execution speed.
You have a choice of getting your semantics of your intructions from already existing sources or go your own way. Building these semantics is a lot of bulk work.
CBMC
CBMC is a powerful bounded model checker for C. It does have a lower level IR called GOTO, but using this as a target would lock us in, lose familiarity, lose compilability. There are significant C projects that use CBMC to check conditions
ESBMC is a comparable fork of CBMC. CBMC can be used to both check for generic problems (use after free, buffer overflow, etc) and also check for user designated properties. Setting these up is quite similar to setting up a unit test harness or fuzzing harness, except there is a better argument for completeness. CBMC can also generate unrolling assumption checks that will show that despte the bounded nature of it’s loop unrolling, it has covered every possible execution path.
https://www.kroening.com/papers/asp-dac2003.pdf Hardware Verification using ANSI-C Programs as a Reference. This is in essence what I’m doing.