Lifting E-Graphs
I submitted a talk to the EGRAPHS workshop and it was accepted! https://pldi26.sigplan.org/details/egraphs-2026-papers/13/Lifting-E-Graphs-A-Function-Isn-t-a-Constant
Between the time when I submitted my abstract and now, while the meat of “there is something here” has not changed, my understanding and best explanation of the thing has been refined.
The whole design is powered by intuition coming from a semantic model manipulating R^n -> R functions in a systematic way. I’m now calling what I previously called a Thinning e-graph https://www.philipzucker.com/thin_egraph/ a Lifting E-Graph, as the word lift is more evocative of what the main operation of interest does on R^n -> R functions.
What’s Wrong with Explicit Names?
There are 3 issues with explicit names
- Generative processes can run off the rails (eqsat). We need fresh names sometimes. As an example
P --> forall x, P | where x freshis basically a valid rewrite for propositions. Sometimes rewrites like this can be useful. We might derive the same thing many many times redundantly with different names if we just gensym them. We can play skolem games and free variable analysis games to try and derive names we know are fresh and repeatable, but this is (subjectively) inelegant. - Missed sharing.
f(g(h(x)))shares no storage withf(g(h(y))). The amount of missed storage opportunity gets worse the deeper and bigger the term. These two things aren’t equal, so I’m not exactly complaining about missed equality. I’m complaining about a missed relationship that can be used for reasoning and compaction. - Too much sharing. This is the surprising one. I think non careful use of explicit names conflates actually disequal objects. The notation
sin(x)actually can refer to distinct mathematical objects that one should at least be aware of the possibility to disambiguate.
The more surprising issue I think is #3. Let’s expand upon that.
Original Sin: X
sin(x) from an ordinary perspective is fine. We’ve lived with the notation for hundreds of years. It works. We know what it means when we see it.
From another perspective it is horribly vague and possibly collapsing distinct entities. We are somehow referring vaguely to the function sin, but are we specifically referring to x |-> sin(x) : R -> R
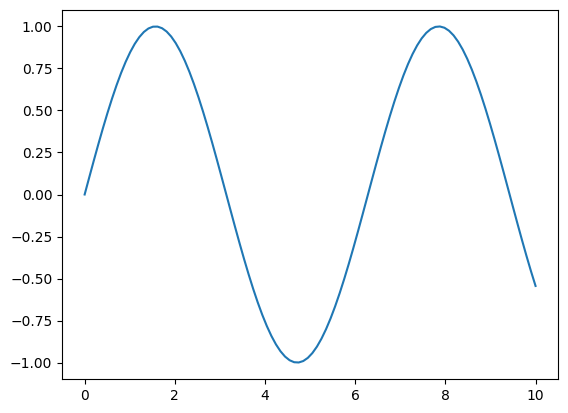
or to x,y |-> sin(x) : R^2 -> R?
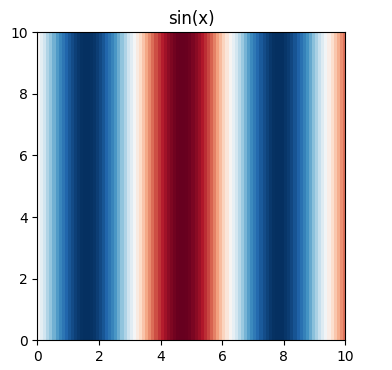
According to a simply typed perspective of the world, these are different things, and in fact can’t even be compared for equality due to type mismatch. The graphs are completely different images. Yet, the notation that suppresses the context x,y |-> or leaves it implicit conflates these two things. It is at least worrying that perhaps in some subtle way this conflation is in essence asserting R^2 = R^1 and from thence chaos ensues.
From this observation come a slogan for today’s design philosophy:
Context is not where a term is, it is part of what a term is
This is not the case for every conception of the word “context”, but it is what I want to do today.
We will choose to not leave out the information of x,y |-> ever. It is a part of the thing we are discussing. For today, we shall consider it basically incoherent to talk about a “bare” sin(x)
Naive Nameless
There is a naive way to achieve this design philosophy using an ordinary egraph / ordinary first order terms.
We can make a different copy of every function symbol for every dimension/context we might be working in and we can refer to variables by (dimension,index) pairs $x_{di}$ rather than by names. For example $x_{10}$ (the zeroth variables in context of size 1) is what previously I would have called x |-> x, $x_{21}$ (the first variable in context of size 2) is what previously I would have called x,y |-> y.
Likewise, we could also disambiguate all the sin into different versions $\sin_d$ depending on the type of it’s argument. If $x_{21}$ has type $R^2 \rightarrow R$ then if sin is going to accept it, it needs to take in arguments of that type. We have $sin_0 : (R^0 \rightarrow R) \rightarrow (R^0 \rightarrow R)$, $sin_1 : (R \rightarrow R) \rightarrow (R \rightarrow R)$, $sin_2 : (R^2 \rightarrow R) \rightarrow (R^2 \rightarrow R)$ and so on.
Really all of these come from the pointwise application of the regular sin function, and this is a parametric polymorphic construction, so this disambiguation is not really that necessary (the index n is derivable from the dimension of sin’s arguments). Still, if we wanted to stay conceptually in a simply typed framework, this is what we’ve go to do.
Ok, great. This carefulness does solve issue #3 of too much sharing. At the same time, we’ve made point #2 of too little sharing both better and worse.
Because we are being nameless by referring to variables by integers, x |-> f(g(h(x))) becomes syntactically the same as y |-> f(g(h(y))) since both become f1(g1(h1(x10))). So sharing has become better in that sense.
On the other hand, now f1(g1(h1(x10))) : R -> R and f2(g2(h2(x20))) : R^2 -> R share absolutely no storage, despite being very similar (again, not equal, because they don’t even have the same type). Perhaps before we could have referred to both as f(g(h(x))), so out ability to share storage for these two cases has gotten worse.
What to do about that?
Lifting
Well, let’s discuss the semantic sense in which f1(g1(h1(x10))) : R -> R and f2(g2(h2(x20))) : R^2 -> R are related.
The latter is a lifted version of the former.
If you gave me an object f1(g1(h1(x10))) : R -> R I could produce the object f2(g2(h2(x20))) : R^2 -> R by merely throwing away the second argument and propagating the first argument. As a python function, this lifting combinator would be written as lambda f: lambda x,y: f(x). This is a lifting operation, and lifting operations have a tractable algebra associated with them. https://www.philipzucker.com/thin1/
Instead of ever storing f2(g2(h2(x20))) : R^2 -> R, I could instead store lift_10(f1(g1(h1(x10)))) : R^2 -> R. The subscript on lift is a bitvector with a 1 if I should keep the argument, or a 0 if throw it away. Again, this all perfectly first order syntactic and simply typed. I could do so as an encoding in a regular egraph. Sharing of substructure is achieved because the two semantically distinct things now share big subterms.
Lifting has some useful properties that one would then encode as rules. The “parametric polymophism” of typical pointwise derived combinators like sin manifests as a rewrite rule sin(lift_i(X)) = lift_i(sin(X)) . This is stating that lift is a homomorphism with respect to typical function symbols / it kind of sort of commutes through them.
In addition, there is sort of a constant propagation rule for liftings lift_i(lift_j(X)) = lift_k(X) where k = i . j
In short, the system we are discussing can be encoded as explicit first order lift combinators with
lift_i(lift_j(X)) = lift_k(X)lift compaction rulesf(lift_i(X), lift_i(Y)) = lift_i(f(X,Y))lift pulling rules
Baking Lift In
These properties of lifting are so simple, ubiquitous and structural that it may make sense to bake them into the very fabric of what a term or an egraph is. This is sweetened by the fact that liftings/thinnings can be represented as compact bitvectors.
Lift is quite simple to represent as a bitvector (a thinning) with a 1 for variables to keep and 0 for variables to drop.
This is pretty compact data, and it isn’t totally crazy I think to steal some bits to pack it alongside the typical eid term/eclass identifier.
Smart Constructor For Lifting
The homomorphism rules can be oriented to float the liftings as high a possible f(lift_i(X), lift_i(Y)) -> lift_i(f(X,Y)). This is a natural rewrite ordering in that the right hand side is the smaller term. A Knuth Bendix Order will achieve this. You should also set the precedence of lift to be low to fix the marginal unary f(lift(X)) -> lift(f(X)) case.
The smart constructor operation will ensure that whenever you build a node with arguments eids that are lifted more than necessary, you get back a fat eid handle to the same interned data regardless of the extra lifting, enabling reduced memory usage and faster lifting relationship comparison.
Whenever you build a new enode, the smart constructor should examine the common lifting of the fat eids of it’s arguments, peel off this lifting, intern the enode, and the put the common lifting back on before returning the fat eid to the user. This is a mechanical way of achieve the lift pull up rule inside the egraph.
As described, this mechanism and the rewrite rule behind it seems pretty elementary and non mysterious to me. It has taken some time and explanation shifting to feel that way.
In the absence of a union find, this lifting pulling smart constructor + fat id makes for an interesting “alpha aware” hash cons. https://www.philipzucker.com/thin_hash_cons_codebruijn/
Pulling lift up corresponds in an interesting way to the co-De Bruijn style of normalizing and representing lambda terms as described in McBride’s Everybody’s Got to Be Somewhere https://arxiv.org/abs/1807.04085 . I have not discussed lambdas at all thus far. I think the considerations of this post are more elementary and that lambdas/binding forms are a layer to add to this more elementary layer.
Note also that by being as thin as possible, the dimensionality can play kind of a nameless free variable analysis. By being part of the fabric of what the term even is, it is less of a problem to make sure that the free variable analysis is up to date before you make some dicey variable rewrite.
Lifting Union Find
But we want an egraph. We need to add a union find to that hash cons.
How do we implement a union find that accepts lifted fat eids?
Because liftings are semantically injective functions, when you union two lifted eids lift_i(a) = lift_i(b), you can peel off the common parts of their liftings and learn a = b.
This is similar to the move you can make in syntactic unification or from equality between algebraic datatypes, which are also injective functions. cons(a, c) = cons(b, c) implies a = b.
If what is left is bare eids e6 = e47 because the two liftings were identical, then it is the ordinary union find action at that point.
It does not even type check to union two objects with different numbers of variables, if a lifting mismatch is due to this, it is a user error.
However, there still remains legitimate cases of unequal thinnings being unioned.
x * 0 = 0 and Redundancies
A concerning counterexample to any discussion of variables in e-graphs is x * 0 = 0. If this is a truly bidirectional equality, it allows x to slip into any location where 0 is used. This feels like a non hygienic scope extrusion, since 0 can appear anywhere, including places where x may not be in scope. Consider using a naive first order encoding of lambdas
lam(y, y * 0)
= lam(y, 0) by y * 0 = 0
= lam(y, x * 0) by 0 = x * 0
Feels bad.
One can perhaps argue for a semantics for which accessing an x not in scope is not a violent error, but instead just returns arbitrary (well typed?) junk. In this case, it is indeed semantically fine to access x if you’re going to just destroy all that information immediately by multiplying by 0.
Still, this semantics fills me with (subjective) discomfort. It feels inelegant. Maybe I’m just a coward.
No, scratch that. I’m definitely a coward. But it in unclear if this discomfort is a manifestation of my cowardice or not.
While I have toyed with the idea of allowing junking / dumping moves https://www.philipzucker.com/dump_calculus/ that are pseudoinverses to lifting, my current understanding is that it is not necessary to do so, and I think a bit more elegant to avoid it.
From the careful scoping/lifting perspective, the actual equation in question is x |-> x * 0 = 0 which is combinatorized into x_10 * lift_0(0) = lift_0(0). Note that since 0 is a constant (a 0-arity function [] |-> 0), it must be lifted into current 1-context x |->.
Both x_10 * lift_0(0) and 0 are actually interned as eids, let’s say x_10 * lift_0(0) -> e47 and 0 -> e6, so the union occurring is union(e47. lift_0(e6)). We do indeed have differing lifts on the left and right side.
The union find can resolve this by picking the orientation / parent to be e6. This results in the rule e47 -> lift_0(e6) which is representable in a lifting annotated parents table, akin to how e48 -> e14 + 7 can be stored in an integer offset annotated parents table in a group union find.
Picking this directionality is required because it “solves” for e47. There is no lifting that will solve for e6 in terms of e47, e6 -> lift_?(e47) DOESN'T WORK. Being in solved form is what enables the simple action of find accumulating an annotation as it traverses the parents table.
It is also possible to be in a situation which neither left or right side is solvable in terns of the other. This situation is luckily still solvable by generating a common fresh constant that both left and right are solvable to left -> annot1(fresh) and right -> annot2(fresh).
The same kind of consideration come in a more elementary was from baking in integer constant multiplications into a union find like 3 * e47 = 2 * e3. More discussion on this lightly asymmetric annotated union find here https://www.philipzucker.com/thin_monus_uf/
As an example that requires this fresh constant generation, consider x,y |-> x*0 = 0*y which combinatorizes to lift_10(x10 * lift_0(0)) = lift_01(lift_0(0) * x10). This ought to be a rarer occurrence and I am almost inclined to not implement it. Neither can be solved in terms of the other, but by generating a fresh eid, there is semantically something that both ought to be solvable to. Let’s say the right hand side has eid e14, lift_0(0) * x10 -> e14. Then we infer there exists a fresh e112 such that e14 -> lift_0(e112) and e47 -> lift_0(e112). Indeed, e112 is semantically the same as 0 and if we assert the x |-> x * 0 = 0 and x |-> 0 * x = 0 first (which is probably the more natural thing to do), the initial example equation x,y |-> x*0 = 0*y would be considered redundant.
This example is somewhat constructed just to show how irreconcilable liftings can occur in a semantically valid way. I am not convinced it is natural to write rules in such a way that a situation like this would show up very often
E-Matching
All of the implementation of a lifting egraph was pretty mechanical without thinking too deeply until I hit e-matching. That is what sent me back to the drawing board to clarify the semantics and first order term model of what I was doing.
A confusing thing is that we have made liftings baked in and somewhat implicit. Should liftings appear in patterns? When should liftings be allowed to be inserted to solve the problem?
I think what I now understand is that there are at least 3 different e-matching problems you might want to solve.
0 = ?x * ?yonly matching on unlifted canonical idlift_010(0) = ?x * ?ymatching a lifted id?lift1 0 = ?lift2 (?x * ?y)matching an TBD arbitrarily lifted id.
The last one is lightly a unification problem (has variables on both sides of the equations), so maybe we can consider that out of scope. It is a somewhat natural thing to ask though.
By far the simplest thing to do, and I think it kind of makes pragmatic sense, is that as soon as you encounter a thinning from the root in the union find during ematching, just don’t traverse that edge. This kind of corresponds to only solving problem 1. The only nodes you’re going to find down that edge will contain redundant variables. It is rarely a good thing to have extra unnecessary variables around (they are expensive for all kinds of reasons), so why even do it? In this case, e-matching is basically identical to ordinary ematching but you do have to compose the thinnings as you are traversing down the argument edges of an enode.
Ok, but let us say we want to do it.
The pattern lift_00(0) = ?x * ?y with x10 * lift_0(0) = lift_0(0) in the egraph should have 2 solutions, {?x -> x20, ?y -> 0} and {?x -> x21, ?y -> 0}. This corresponds to matching against the target x,y |-> 0 and getting the two solutions x,y |-> x * 0 and x,y |-> y * 0. If we pattern match over an higher lifting of 0 like lift_0000(0), we’d expect 4 solutions, and so on. These are enumerating all the variables you can place in that spot that get annihilated by 0. In terms of the liftings, they are all the ways of solving the equation lift_00 = lift_? . lift_0 which has two solutions lift_10 and lift_01. In words, to throw away both arguments lift_00, you can either throw away the second argument and the one left lift_10 . lift_0, or you can throw away the first argument and then throw away the one left lift_01 . lift_0.
lift_0 = lift_? . lift_00 problems of this shape have no solutions in liftings. Liftings monotonically increase the number of arguments, and lift_00 has already lifted to taking in 2 redundant arguments whereas the left hand side lift_0 only takes in 1 redundant argument.
Fully writing out the derivations of these two matches:
lift_00(0) =? ?x * ?y
lift_01(lift_0(0)) =? ?x * ?y by lift factoring (motivated by the next move)
lift_01(x10 * lift0(0)) =? ?x * ?y by lift_0(0) = x10 * lift0(0)
lift_01(x10) * lift_01(lift0(0)) =? ?x * ?y by mul-homomorphism lift(mul(X,Y)) = mul(lift(X), lift(Y))
?x -> lift_01(x10), ?y -> lift_00(0) by the usual syntactic matching of *
But you can also use the other factoring
lift_00(0) =? ?x * ?y
lift_10(lift_0(0)) =? ?x * ?y by the other lift factoring (motivated by the next move)
lift_10(x10 * lift0(0)) =? ?x * ?y by lift_0(0) = x10 * lift0(0)
lift_10(x10) * lift_10(lift0(0)) =? ?x * ?y by mul-homomorphism lift(mul(X,Y)) = mul(lift(X), lift(Y))
?x -> lift_10(x10), ?y -> lift_00(0) by the usual syntactic matching of *
Bits and Bobbles
The Picture
Some of the e-graph’s success it due to this picture

Like in my picture here https://www.philipzucker.com/egraph2024_talk_done/

we do not want to represent eclasses as a dotted boundary, but instead as dotted arrows representing the union find parents relation. Then the thinnings that appear inside the union find can be represented visually.
The thinning egraph can be visualized by thickening all the edges (both solid child edges and dashed union find edges) into “buses” like a digital circuit. These buses have N lines in them for the N variables in context. The 0 in a thinning appears as lines that end in an cross out x in between nodes. Inside the bus, lines never cross each other because thinnings are about strictly monotonic ordered mappings.
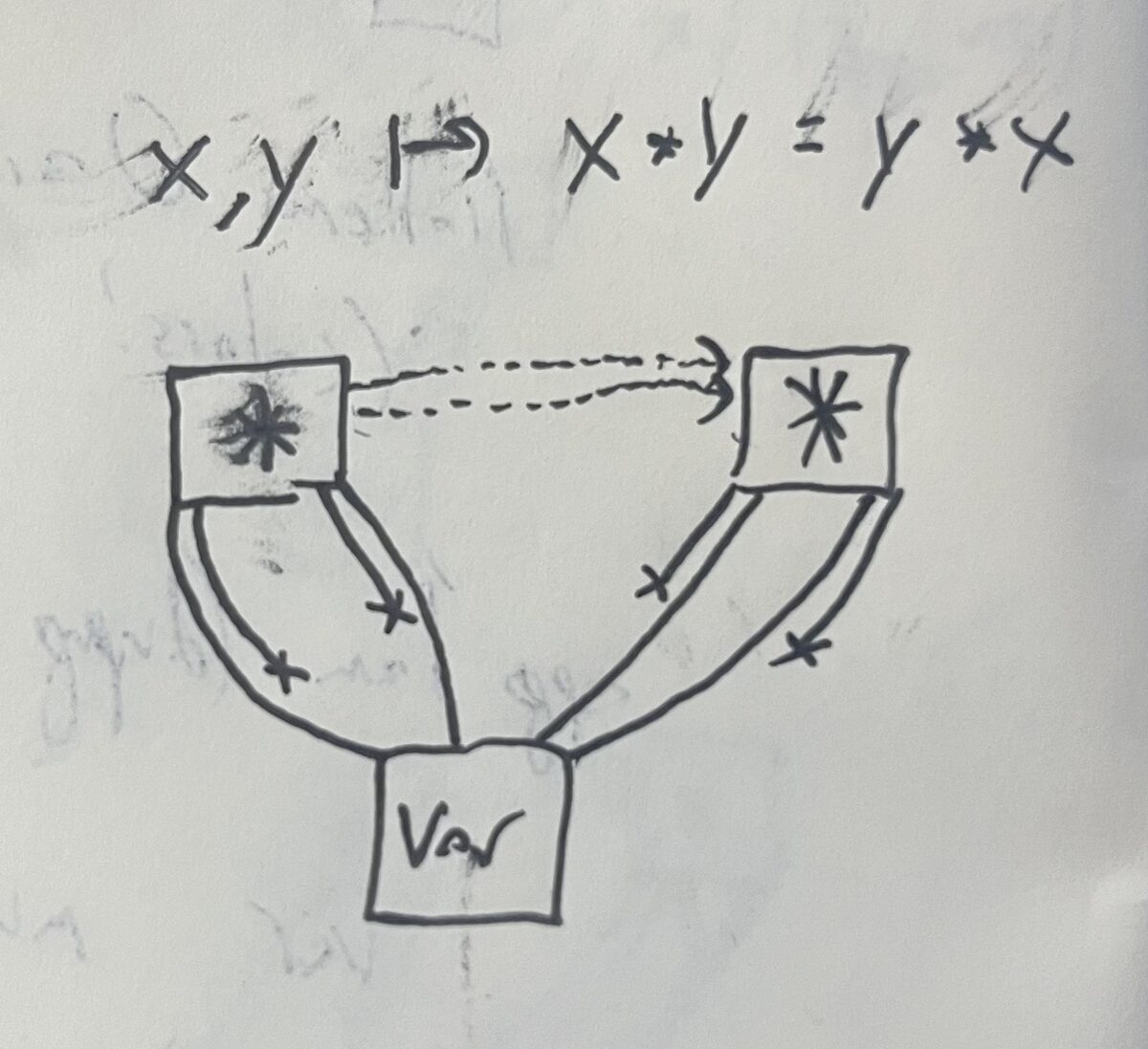
Here is an example lifting egraph resulting from x,y |-> x * y = y * x aka lift_10(var) * lift_01(var) = lift_01(var) * lift_10(var). The thinning on the union find edge is an identity thinning, so it has no lines endings inside it.
Today I also saw https://www.csl.sri.com/papers/bachmairtiwari00/cade00-CC.pdf abstract congruence closure by Bachmair and Tiwari which has a similar kind of diagram
Knuth Bendix Model
cnf(mulname, axiom, mul(id, l(zero)) = e0).
cnf(union, axiom, e0 = l(zero)).
cnf(mul_zero_id, axiom, mul(zero,zero) = e2).
cnf(mulzerozero, axiom, e2 = zero).
cnf(linj, axiom , l(X) != l(Y) | X = Y).
cnf(lift_mul, axiom, l(mul(X,Y)) = mul(l(X),l(Y))). % homomorphism
A simplified model with only a single lifting l (which I think can be interpreted as roughly lift_1111110, a family of thinnings that always drops that last (or first) variable) was very helpful for me to play around on paper.
Eprover is flexible enough to add an injectivity axiom and state the homomorphism lifting pullthrough axiom. Combined with ground equations, this seems to complete with a knuth bendix ordering with weight(e) = semantic dimension and w(l) = 1 and l low in the precedence. The weight proportional to dimension and precedence is necessary to have equations orient into e47 -> l(e6) in the appropriate way with all the thinnings on the right.
I am not entirely sure that this recipe for the ordering will always complete, but it feels plausible (70%) to me.
Comparing with Slotted
I’ve been discussing with Rudi a lot about slotted e-graphs and we’ve been trying to find the middle ground of this thinning perspective and the slotted perspective.
The difference is very evocative of two major camps dealing with bindings: nominal https://www.cl.cam.ac.uk/~amp12/papers/nomlfo/nomlfo-draft.pdf vs presheafy/functorial/family https://dimasamoz.github.io/docs/talks/2024-04-WG6.pdf (for lack of better words) stuff. I think Rudi has his own sources, but my awareness of thinnings does come filtered down through interconnections with this previous work (via McBride’s mastodon comments). Direct exposure to those papers does me little good though, since I have no idea what they are talking about. I am not a category theory guy.
We’ve been tinkering https://github.com/philzook58/slotteduf on “ordered slotted” which seems to be an intermediate construction that lives somewhere in the world between slotted and liftings egraphs.
Thinnings have at least two representations. the bitvector representation 10001 or just listing the indices of the keeps [0,4] are close to being isomorphic. Attaching this latter representation to eids is seemingly roughly the same as a slotted eid.
The reason they are not isomorphic is that we have lost the total length of the bitvector. We do not know if [0,4] orresponds to 10001 or 100010 or 10001000000000000.... I am inclined to interpret the slotted notion of thinning [0,4] as mediating from a common countably infinite domain of variables (the thinning with infinite trailing zeros). Everything is in ultimately considered in the same mega context and you have global names (number labels) for stuff. Something something (co)slice category. Rudi seems inclined to consider it to represent the shortest length bitvector 10001
Rudi’s interpretation of [0,4] is that the eid has been applied to slot arguments [0,4] which is hard to see in my model.
Before interning, slotted egraphs perform a canonical shape computation argument by argument to pull out permutations. An ordering is figured out for the slots by using the structure of the node.
If slots are considered to be ordered and permutations no longer baked in, shape computation becomes much easier (at the same time the egraph is not doing permutation stuff for you, so you are perhaps losing something. This is a tradeoff, not a free lunch). You instead take all the slots [4,7,100] and just keep them in order but now label them 1 through n [0,1,2] with a thinning that says 0 maps to 4, 1 maps to 7 and 2 maps to 100.
McBride did have some mysterious comment about a ordered universe of constants as being nice.
The names vs nameless isn’t perhaps exactly the axis on which the difference lies. One can also have ordered slots, and one can have named thinnings as evidence for the subrecord relation rather than the subsequence relation.
Binders
Lambda or binder is another smart constructor, but one that needs to peel off the variables bound from the eid of the child while it is pulling the lifting annotation up. Lambda does not pure commute with liftings, it changes the lifting as it comes up through.
In a curious way, lambdas are like a projection. They remove a variable, the same way filling it in with 0 might do. They do some by also changing the type of the object to be a functional type, so this “projection” is not lossy.
Connections
Liftings are indeed exactly thinnings and weakenings and |-> is the same as |-. I just think the change of terminology and notation helps make the description easier to digest. To my ear, thinning and weakening seem to connote the exact opposite of the operation I think is happening, taking a low dimensional function and turning it into a high dimensional one.
Deeper waters:
- Semi simplicial categories
- Cubical categories
- Families
- Presheaf models
- Explicit Weakening calculi. https://arxiv.org/abs/2412.03124 https://hal.science/hal-00384683/document
- partially applied composition
sin .and Yoneda stuff
There are connections here. What I have done is tried to distill away as much complexity as possible. I think lifting egraphs stand alone without these things, but the connections may enrich your understanding. Everyone has different stuff that works for them. I am not a math or theory maximalist. I have aspects I like, aspects I understand, aspects I don’t like, aspects I don’t understand, aspects I wish I understood.
I don’t think I actually am good at abstraction. What I can do is have 3 concrete examples in superposition in my head, which is a little different than having a black box conception. This superposition may explain why I punctuate and use notation so inconsistently. Rapid oscillation between python, pseudo-haskell, term rewriting, pictures, and latex is how I am.
Nominal vs Nameless
The assymetric union find as a way of storing proof relevant tree (forest) like partial orders. The tree thing makes sense because union finds are trees. The proof relevant part is necessary because the proof data (edge annotation) tells you where to plug in a new fact into your trees. Positive offset and integer divisibility do have this proof relevant partial order flavor.
In this sense, perhaps the asymmetric union find is a nice version of a inequality union find that does not require search. https://www.philipzucker.com/asymmetric_complete/
Bits and Bobbles
It isn’t persay terrible to assume that sin(x) uniquely corresponds to always talking about $R^\infty \rightarrow R$ or similarly (Name -> R) -> R, an environment passing semantics. It’s a different style. It does seem off to bring names into the discussion or bring infinity into the discussion in order to discuss R^2 -> R. It is reminiscent of the age old synthetic vs analysis approach. Intrinsic vs extrinsic. Is a sphere best described by cutting it out of R^3 or by piecing together 2d coordinate patches? What is “best”? What is most beautiful? What fits the clunky notation or framework you’ve got? The lifting approach is a bit more “well typed”. “Well typed” often kind of sucks though. It is brittle and you can end up in type level programming hell if you don’t use taste. You’ve pushed the pain from the ordinary stuff to the type level stuff, which is automatic. But when it stops being automatic, now you’re just working in a worse environment.
Encoding is inelegant and each tiny inelegance chokes you the further you try and go with it. Ultimately, inelegance is a limitation on scale. This limitation is soft and therefore even more insidious. I can’t argue against people who don’t feel the fear of soft limitations. There will never be an inarguable point at which you say “I can go no further”, but the bog always wins. You lie down, the mud and reeds enters your mouth and you die. Encodings are the complexity demon opening it’s jaws and grinning.
The too little and too much sharing story is reminiscent of the Hash Cons Modulo alpha paper.
eids are often 32 or 64 bits, and typical egraphs do not grow to that size, leaving some headspace for at least of byte of metadata in there, maybe more. You could also perhaps play some run length encoding tricks, etc, depending on the nature of the thinnings you expect. If you need more than 8 variables in scope at once, you could reify the lifting to an enode like the encoding above or start allocating bit vectors kind of like a bigint implementation.
It is not necessary to encode these properties as rules (although perhaps one still should if you want to retrofit this into a preexisting e-graph system as an encoding).
This is not exactly the same as how I developed the ideas though. The ideas developed from just the implementation mechanism of thinnings as bitvectors seeming so clean and useful.
x |-> x : R -> R is the identity function. x,y |-> x : R^2 -> R is a projection function that extracts the first dimension. All bare uses of variables can be expressed as liftings of the identity function. Because of this, we only need to intern a single variable For example x51 (the 1th variable in context of size 5) is defined to be x51 := lift_01000(x10) or another example x40 := lift_1000(x10) (remember that I have chosen the convention of 0 indexing variables). We could give x10 a special name, such as var or id.
sin(x) can also be given meaning according to an environmant passing semantics or more subtly by saying that x can take on different values in the model but sin is pinned to mean mathematical sine. This is the sort of thing that happens when you have uninterpred constants like x combined with inteprreted functions / constants in an SMT solve.
Top down e-matching is using the memo f(l(e3), l(e5)) -> l(e17) and union find rules e4 -> l(e6) in the opposite of their natural direction. We expand memo to turn an eid into an enode, and we run the union find in reverse to enumerate the eids in the eclass.
If we are matching lift_001(e17), first we can enumerate the eids in the eclass by running the union find backwards. If the edge in the union find has a thinning that
- Discomfort about scope escape. What to do about
x*0 = 0? What about when you want to push a term through a binder (change scope a little bit)?
Hmm. I feel like I’m flip flopping between a picture where eids correspond to specific enodes and not. It depends on whether we want the enode rules to be of the form f(l(e)) -> e or if we allow f(l(e)) -> l(e) where the eids can be destructively updated in the memo table. In terms of an enode list, refusing to travese redundances for ematching would correspond to just ignoring enode that has a lifted eid.
l0(e6) =? ?x * ?y
We can follow the union find edge backwards
e47 -> l0(e6)
to
e47 =? ?x * ?y
Then expand the node through usjing memo table entry x10 * l0(e6) -> e47 to
x10 * l0(e6) =? ?x * ?y
Then apply an ordinary mathing move to
x10 =? ?x, l0(e6) =? ?y which can be oriented into a substitution.
e6 =? ?x * ?y cannot use e47 -> l0(e6) because there is no l0 to peel off.
l_00(e6) =? ?x * ?y. l_00 can be decomposted to two way to expose l_0(e6) l10 . l0 = l00 and l01 . l0 = l00
- `0 = ?lift (?x * ? y)
- `lift_0(0) = (?x * ? y)
E-matching confused the hell out of me and sent me out spinning
e47 -> lift_00(enew) where lift_00 is coming from the intersection of the two lifting bitvectors lift_10 and lift_01 (the example is a little too cute and conflates a few things).
Note change this example to x,y |-> x*0 = 0*y
It is also possible to union x,y |-> x*0 = y*0 which combinatorizes to lift_10(x10 * lift_0(0)) = lift_01(x10 * lift_0(0)). This ought to be a rarer occurrnce and I am almost inclined to not implement it. Neither can be solved in terms of the other, but by generating a fresh eid, there is semantically something that both ought to be solvable to. e47 -> lift_00(enew) where lift_00 is coming from the intersection of the two lifting bitvectors lift_10 and lift_01 (the example is a little too cute and conflates a few things).
from dataclasses import dataclass, field
type Thin = list[bool]
type Id = tuple[Thin, int]
def ctx(self, x : Id) -> int:
return len(x[0])
@dataclass
class Node:
f : str
args : tuple[Id, ...]
@dataclass
class EGraph:
memo : dict[Node, int] = field(default_factory=dict)
uf : list[Id] = field(default_factory=list)
def app(self, f : str, *args) -> Id:
assert all(ctx(arg) == ctx(args[0]) for arg in args)
N = ctx(args[0])
common = [False] * N
for arg in args:
common = [c or a for c,a in zip(common, arg[0])] # bitwise or of all arguments
newargs = []
for arg in args:
arg =
node = Node(f, tuple(args))
id = self.memo.get(node)
if id is None:
id = len(self.)
self.memo[node] =
else:
return (comp(common, id[0]), id[1])
def var(self, n : int, j : int):
thin = [False] * n
thin[j] = True
return (tuple(thin), self.memo.get(()))
def find(self, x : Id) -> Id:
...
def union(self, x : Id, y : Id) -> Id:
assert ctx(x) == ctx(y)
def nodes_in_class():
def ematch(self):
Very confused what I am looking at with the ordered slotted egraph.
Sound ematching, not complete.
Maybe I shouldn’t traverse redudnancy edges during ematching anyway, because those matches probably suck. They are going to be searching through dump expressions.
Seed roots with non dump redundant pieces. This also means rebuilding may not want to compact away as much.
equivalraince l(f(X,Y)) = f(l(X), l(Y)) is used to pull l up during canonization, but also can be used during ematching to pull l into the current target term to get f heads to match l(f(e1,e2)) =? f(X,Y) f(l(e1), l(e2)) =? f(X,Y) {X =? l(e1), Y =? l(e2)}
traversing up e -> ll(etop) becomes etop -> ddd(e) which is not fun.
((XY)Z) associativity is no problemo.
Ok what about lambda then. Lambda is not equivariant. lam(l1(B)) = l2(lam(B))
l(e) = f(X,g(Y,Z)) l(f(e1,e2)) = f(X,g(Y,Z)) f(l(e1),l(e2)) = .. l(e1) = X, l(e2) = g(Y,Z)
l being least in lpo does track. That would pull l to the outside. l(f(a,f(b,c))) dump is uneccessary?
What if l was just add a variable to front. Always l1 l0 with the rest being understand to be true.
l0(l1(l0()))
coherent. uhh. No. But this won’t let us do as much sharing. y = l0(l1(v)) x =? l1(l0(v))? no.
shift(l)
l(n, m, X)
Huh. No.
pulling l outward but always e -> l(e) is tought to get to happen.
dump nodes floordiv(x, 3) is kind of a skolem node. We could just not normalize these further. (even thought dump dump probably merges and dumps should push down)
l
e -> l(e) then we want e > l
f(l(X)) -> l(f(X)) then we want f > l
So l has to be least in the ordered. Every eid should have a weight corresponding to it’s size.
In this simplified subsystem, I can’t have incompatable l0(e) = l1(e).
x != y % not sure it can do much with this. swap(x) = y swap(y) = x swap(swap(X)) = X
f(e1(x,y), ) -> e2(x)
swap(e2(x)) = e2(y) ordering the slots. Is this the thing rudi and I did? maybe. x > y > z, normalize all e. Is there a point to e(x,y,z) form? We just know it’ll be 0,1,2?
x + y = x + swap(x)
e(x,y) = e2(y) e(x,y) = swap(y)
e -> swap(e) implies e > swap swap weight = 0? swap(swap(X)) = X swap(f(X,Y)) = f(swap(X), swap(Y)) swap(x) = y swap(y) = x
x:1,swap:1,y:2 ? swap(x) = y is same weight, it will prefer swaps y -> swap(x) swap_xy == weight(x) - weight(y) ? for multivariate. Analog of weight(lift) = cod(lift) - dom(lift) x > y > z > … to get sorting.
e1(x,y) = e2(y) swap(e1(x,y)) = swap(e2(y)) e1(y,x) = e2(x) sure. x,y,z
e2(x) = swap(e1(y,x))
hmm. My previous example did loop.
e at different level should never be being compared directly without l in between. And at a level it’s abritrary
lpo = the worst subterm gets better (what is worst? The worst term is the top one)
https://www.jaist.ac.jp/project/maxcomp/
https://github.com/yaspar-org/semi-persistent/blob/main/egraph/doc/design/00-table-of-contents.md
ordered slotted is perhaps a mapping from infinite context e(v0, v1,v4) = [true, true, false, false, true, false, ….]
A mediation between nominal and presheafy thinny stuff?
ordered slotted had an easier canonicalization function. We just compact them into sorted order. This is not how full slotted worked, which normalized argument by argument.
origina
%%file /tmp/swap.p
cnf(swap, axiom, swap(x) = y).
cnf(swapy, axiom, swap(y) = x).
cnf(swap_involution, axiom, swap(swap(X)) = X).
cnf(swap_mul, axiom, swap(mul(X,Y)) = mul(swap(X), swap(Y))).
cnf(swap_zero, axiom, swap(zero) = zero).
cnf(mul_zero, axiom, mul(zero,zero) = zero).
cnf(mulzero, axiom, mul(x,zero) = zero).
cnf(mulzero, axiom, mul(y,zero) = zero).
cnf(mulxy, axiom, mul(x,y) = mul(y,x)).
% mul(swap(X), Y) = swap(mul(X, swap(Y))). That's a good point. remove swap from first and add to all other args.
Writing /tmp/swap.p
! metis /tmp/swap.p
^C
Hmm. So I can’t get kbo to work. I think slotted would want to push swap down? Maybe this is why I need e(x,y,z)?
x,y high to get rid of them in redundancies? swap low? to push swap(mul) -> mul(swap, swap) ? symmettries screw you?
! eprover-ho -t LPO4 -s --auto --precedence="y > x > mul > zero > swap" --print-saturated /tmp/swap.p
% Preprocessing class: FSSSSMSSSSSNFFN.
% Configuration: G-E--_302_C18_F1_URBAN_RG_S04BN
% (lift_lambdas = 1, lambda_to_forall = 1,unroll_only_formulas = 1, sine = Auto)
% No SInE strategy applied
% Search class: FUUPS-FFSM21-SFFFFFNN
% partial match(1): FUUPS-FFSF21-SFFFFFNN
% Configuration: G-E--_208_C12_00_F1_SE_CS_PI_SP_PS_S5PRR_RG_S04AN
% Presaturation interreduction done
% No proof found!
% SZS status Satisfiable
% Processed positive unit clauses:
cnf(i_0_9, plain, (y=swap(x))).
cnf(i_0_13, plain, (swap(zero)=zero)).
cnf(i_0_11, plain, (swap(swap(X1))=X1)).
cnf(i_0_15, plain, (mul(x,zero)=zero)).
cnf(i_0_14, plain, (mul(zero,zero)=zero)).
cnf(i_0_19, plain, (mul(swap(X1),X2)=swap(mul(X1,swap(X2))))).
cnf(i_0_26, plain, (mul(zero,swap(X1))=swap(mul(zero,X1)))).
% Processed negative unit clauses:
% Processed non-unit clauses:
% Unprocessed positive unit clauses:
% Unprocessed negative unit clauses:
% Unprocessed non-unit clauses:
! eprover-ho -t KBO6 -s --auto --precedence="mul > zero > x > y > swap" --order-weights="mul:1,zero:1,swap:1,x:3,y:4" --print-saturated /tmp/swap.p
% Preprocessing class: FSSSSMSSSSSNFFN.
% Configuration: G-E--_302_C18_F1_URBAN_RG_S04BN
% (lift_lambdas = 1, lambda_to_forall = 1,unroll_only_formulas = 1, sine = Auto)
% No SInE strategy applied
% Search class: FUUPS-FFSS21-SFFFFFNN
% partial match(1): FUUPS-FFSF21-SFFFFFNN
% Configuration: G-E--_208_C12_00_F1_SE_CS_PI_SP_PS_S5PRR_RG_S04AN
setting user weights
^C
! eprover-ho --auto --cpu-limit=1 --silent --proof-object /tmp/test.p
% Preprocessing class: FSMSSMSSSSSNFFN.
% Configuration: G-E--_208_C18_F1_SE_CS_SOS_SP_PS_S5PRR_RG_S04AN
% (lift_lambdas = 1, lambda_to_forall = 1,unroll_only_formulas = 1, sine = Auto)
% No SInE strategy applied
% Search class: FGHSF-FFSF21-SFFFFFNN
% Configuration: SAT001_MinMin_p005000_rr_RG
% Presaturation interreduction done
% Proof found!
% SZS status Unsatisfiable
% SZS output start CNFRefutation
cnf(clause_4, negated_conjecture, (f(X2)=X2|~big_f(X1,f(X2))|X1!=g(X2)), file('/tmp/test.p', clause_4)).
cnf(clause_6, negated_conjecture, (big_f(X1,f(X2))|f(X2)=X2|X1!=g(X2)), file('/tmp/test.p', clause_6)).
cnf(clause_9, negated_conjecture, (big_f(h(X1,X2),f(X1))|h(X1,X2)=X2|f(X1)!=X1), file('/tmp/test.p', clause_9)).
cnf(clause_10, negated_conjecture, (f(X1)!=X1|h(X1,X2)!=X2|~big_f(h(X1,X2),f(X1))), file('/tmp/test.p', clause_10)).
cnf(clause_1, axiom, (X1=a|~big_f(X1,X2)), file('/tmp/test.p', clause_1)).
cnf(clause_3, axiom, (big_f(X1,X2)|X1!=a|X2!=b), file('/tmp/test.p', clause_3)).
cnf(c_0_6, negated_conjecture, (f(X2)=X2|~big_f(X1,f(X2))|X1!=g(X2)), inference(fof_simplification,[status(thm)],[clause_4])).
cnf(c_0_7, negated_conjecture, (big_f(X1,f(X2))|f(X2)=X2|X1!=g(X2)), inference(fof_simplification,[status(thm)],[clause_6])).
cnf(c_0_8, negated_conjecture, (f(X2)=X2|~big_f(X1,f(X2))|X1!=g(X2)), c_0_6).
cnf(c_0_9, negated_conjecture, (big_f(h(X1,X2),f(X1))|h(X1,X2)=X2|f(X1)!=X1), inference(fof_simplification,[status(thm)],[clause_9])).
cnf(c_0_10, negated_conjecture, (big_f(X1,f(X2))|f(X2)=X2|X1!=g(X2)), c_0_7).
cnf(c_0_11, negated_conjecture, (f(X1)=X1|~big_f(g(X1),f(X1))), inference(er,[status(thm)],[c_0_8])).
cnf(c_0_12, negated_conjecture, (f(X1)!=X1|h(X1,X2)!=X2|~big_f(h(X1,X2),f(X1))), inference(fof_simplification,[status(thm)],[clause_10])).
cnf(c_0_13, plain, (X1=a|~big_f(X1,X2)), inference(fof_simplification,[status(thm)],[clause_1])).
cnf(c_0_14, negated_conjecture, (big_f(h(X1,X2),f(X1))|h(X1,X2)=X2|f(X1)!=X1), c_0_9).
cnf(c_0_15, negated_conjecture, (f(X1)=X1), inference(csr,[status(thm)],[inference(er,[status(thm)],[c_0_10]), c_0_11])).
cnf(c_0_16, negated_conjecture, (f(X1)!=X1|h(X1,X2)!=X2|~big_f(h(X1,X2),f(X1))), c_0_12).
cnf(c_0_17, plain, (X1=a|~big_f(X1,X2)), c_0_13).
cnf(c_0_18, negated_conjecture, (h(X1,X2)=X2|big_f(h(X1,X2),X1)), inference(cn,[status(thm)],[inference(rw,[status(thm)],[inference(rw,[status(thm)],[c_0_14, c_0_15]), c_0_15])])).
cnf(c_0_19, plain, (big_f(X1,X2)|X1!=a|X2!=b), inference(fof_simplification,[status(thm)],[clause_3])).
cnf(c_0_20, negated_conjecture, (h(X1,X2)!=X2|~big_f(h(X1,X2),X1)), inference(cn,[status(thm)],[inference(rw,[status(thm)],[inference(rw,[status(thm)],[c_0_16, c_0_15]), c_0_15])])).
cnf(c_0_21, negated_conjecture, (h(X1,X2)=a|h(X1,X2)=X2), inference(spm,[status(thm)],[c_0_17, c_0_18])).
cnf(c_0_22, plain, (big_f(X1,X2)|X1!=a|X2!=b), c_0_19).
cnf(c_0_23, negated_conjecture, (h(X1,X2)=a|~big_f(X2,X1)), inference(spm,[status(thm)],[c_0_20, c_0_21])).
cnf(c_0_24, plain, (big_f(a,b)), inference(er,[status(thm)],[inference(er,[status(thm)],[c_0_22])])).
cnf(c_0_25, negated_conjecture, (~big_f(a,X1)), inference(er,[status(thm)],[inference(spm,[status(thm)],[c_0_20, c_0_23])])).
cnf(c_0_26, plain, ($false), inference(sr,[status(thm)],[c_0_24, c_0_25]), ['proof']).
% SZS output end CNFRefutation
%%file /tmp/lift.p
cnf(mulname, axiom, mul(id, l(zero)) = e0).
cnf(union, axiom, e0 = l(zero)).
cnf(redundnant, axiom, mul(l(id), l(l(zero))) = l(l(zero))). % if you don't have "union" injectivity + homo will derive it.
cnf(mul_id_id, axiom, mul(id,id) = e1). % x**2. no particular identities apply
cnf(mul_zero_id, axiom, mul(zero,zero) = e2).
cnf(mulzerozero, axiom, e2 = zero).
cnf(mul_comm, axiom, mul(id, l(zero)) = mul(l(zero),id)).
cnf(mul_assoc, axiom, mul(id,mul(id,l(zero))) = mul(mul(id,id),l(zero))).
cnf(linj, axiom , l(X) != l(Y) | X = Y).
%cnf(lequivf, axiom, l(f(X)) = f(l(X))).
cnf(mul_homo, axiom, l(mul(X,Y)) = mul(l(X),l(Y))).
Overwriting /tmp/lift.p
! eprover-ho --precedence="mul > zero > e1 > e0 > e2 > id > l" -t LPO4 /tmp/lift.p --silent --print-oriented-eqlits-as-rules --print-saturated
% (lift_lambdas = 1, lambda_to_forall = 1,unroll_only_formulas = 1, sine = (null))
^C
! eprover-ho --precedence="mul > zero > id > e2 > e0 > e1 > l" -t KBO6 --order-weights="id:2,zero:1,l:1,e0:2,e1:2,e2:1,mul:1" /tmp/lift.p --silent --print-oriented-eqlits-as-rules --print-saturated
% (lift_lambdas = 1, lambda_to_forall = 1,unroll_only_formulas = 1, sine = (null))
setting user weights
% No proof found!
% SZS status Satisfiable
% Processed positive unit clauses:
cnf(i_0_16, plain, (zero->e2)).
cnf(i_0_12, plain, (e0->l(e2))).
cnf(i_0_14, plain, (mul(id,id)->e1)).
cnf(i_0_15, plain, (mul(e2,e2)->e2)).
cnf(i_0_11, plain, (mul(id,l(e2))->l(e2))).
cnf(i_0_20, plain, (mul(l(X1),l(X2))->l(mul(X1,X2)))).
cnf(i_0_17, plain, (mul(l(e2),id)->l(e2))).
cnf(i_0_18, plain, (mul(e1,l(e2))->l(e2))).
% Processed negative unit clauses:
% Processed non-unit clauses:
cnf(i_0_19, plain, (X1->X2|l(X1)!->l(X2))).
% Unprocessed positive unit clauses:
% Unprocessed negative unit clauses:
% Unprocessed non-unit clauses:
%%file /tmp/lift.p
cnf(a1, axiom, l(e1) = e2).
%cnf(a2, axiom, l(e2) = e3).
cnf(a3, axiom, f(l(e1)) = e4).
% l injective also
cnf(linj, axiom , l(X) != l(Y) | X = Y).
cnf(lequivf, axiom, l(f(X)) = f(l(X))).
Writing /tmp/lift.p
! metis /tmp/lift.p
^C
! eprover-ho --print-oriented-eqlits-as-rules --term-ordering=LPO4 --precedence="f > e2 > e4 > e1 > l" --print-saturated /tmp/lift.p
tree-like proof relevant partial orders. I expected to have to sometimes do LCA or traverse down the uf?
unary rewriting theory combination. If I have a normalization procedure for a string system encoded as unary symbols, I don’t think I can actually hurt it by adding in new ground eqautions? Including ones.
Slotted - information goes down, thinning information goes up thin is alpha euqal on the nose. slotted is disequal but g related
String knuth bendix with “fat” characters coproduct knuth bendix.
Frex
Tower of equivalances
sin(pi (?x + 1)) = cos(pi ?x)
Ematching needs an unapply interface that is group aware?
offset, linear enodes, proofs need to record how ematching worked.
versioned egraphs on edges?
Representations of Relations. But we also have things on the nodes. Convert constraint graphs into constraint trees
Skolems fn reify(x : FatId) -> RawId
What the hell just happened in ordered slotted v10 = lambda *args: args[10] sin is still lifted to sin’
AppliedId
e12(2,4,6) f(v1,v0) is fine. Arguments are not linked to slots.
Using the opposite form of thinning. Sure. type Wide = list[int]
Named thinnings. Maybe this is a useful concept to figure out what is the relation of thinning and slotted/redundancy. A thinning is a bitvector recipe saying how to find one list as a subsequence of anothet list. A named thinning is a boolean valued struct as a recipe on how to extract a subrecord from another record (take a subset of the keys/names). The *args combinators I wrote in my blog post can be made to work on **kwargs by using named thinnings. This can all be discussed without the concept of renaming, I dunno if it is useful without renaming though.
Named thinning + permutative renamings does seem like an independent factoring of partial injective renamings.Philip Zucker: Using records for the sin cos model feels weird but is fine. Instead of R^3, use {x : R, y: R, z : R}. Its still mathematical.
My symbols were all (T -> R) -> (T -> R) lifted, but Var wasn’t
Id PComp(Const())
Maybe PComp is fused with App. Or
App == PComp def pcomp(f): return lambda g0: lmabda g1: … lambda args: def app(f, g): return lambdags: lambda args: f(g(args), [g(args) for g in gs])
enum Node { App(Node, Node), Symbol( name : String, arity : usize) PComp //Id }
Var = Symbol(“Id”, arity=1)
type NThin = dict[str, bool]
def nthin(t : NThin, d : dict) -> dict:
return {k : v for k,v in d.items() if t[k]}
def nlift(t : NThin, f):
return lambda **kwargs: f(**nthin(t, kwargs))
# oh interesting. They have their own defaults... But then lift needs to carry the default? And dump is a no-op
def foo(x=0, y=1):
return x - y
nlift({"x": True, "y": True, "z" : False}, foo)(x=10, y=20, z=200)
-10
def replace_thin(t : dict, d : dict) -> dict:
return {**d, **t}
def rlift(t, f):
return lambda **kwargs: f(**replace_thin(t, kwargs))
rlift({"y": 100}, foo)(x=3)
-97