Alpha Equivalent Hash Consing with Thinnings
Another step on a journey to a thinning egraph.
I previously discussed
- https://www.philipzucker.com/thin1/ Thinnings are descriptions of how to prune a list down. Concretely, they are a bitvector of which pieces you take and which you leave. This pruning is related to weakening of list-like contexts/environments.
- https://www.philipzucker.com/thin_monus_uf/ How you can have a union find with thinning annotations on the edges. This can be seen as a union find describing sublist relationships for opaque identifiers in addition to equality relationships.
Here I show a kind of alpha invariant hash cons that uses thinnings. This is a “co de bruijn” style hash cons using similar ideas to McBride’s https://arxiv.org/pdf/1807.04085 Everybody’s Got To Be Somewhere (indeed this line of thought was kicked off by some stuff McBride said on Mastodon).
Every child of a node in the hash cons has a thinning (which is a bitvector) attached to describe how to remove (thin) any variable from context that won’t be used. By composing the thinnings and tracking its strands as you traverse down the term, you can know which variable you are referring to. Once you get all the way down to a variable, there is only one thing in context. Because of this, there is only 1 variable node in the hash cons.
I don’t know if this image is going to help or hurt understanding, but it is worth a shot. The dots here are where the strands die. They die when no subterm is going to use that variable. lam nodes generate a new strand at the front. Strands are kept in order. Strands “branch” but are kept in order into the children of an applied symbol like f or g.
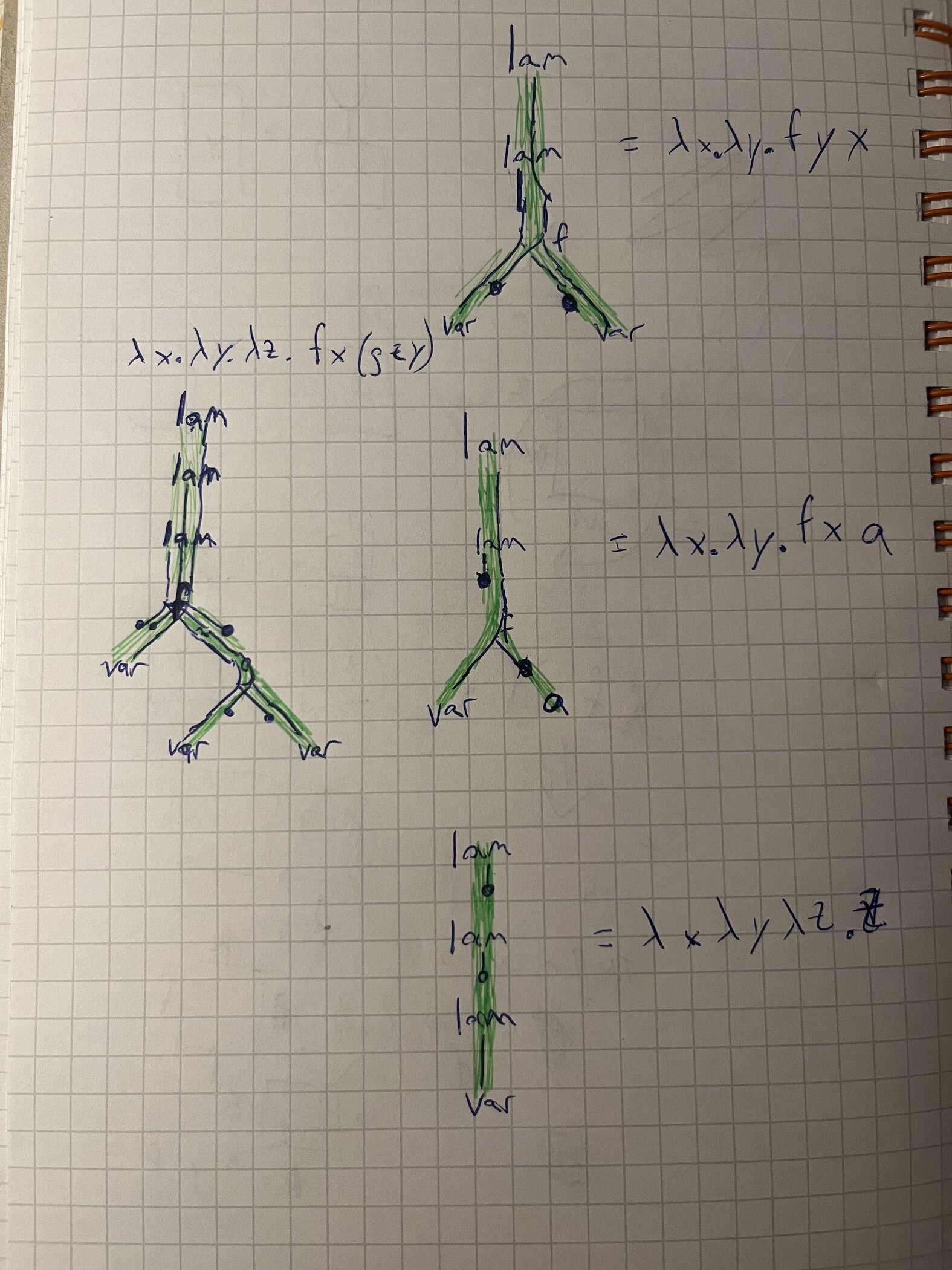
Because the thinnings keep things as thin as possible (everybody’s got to be somewhere), they also look a bit like a free variable analysis on the hash cons.
This thinning hash cons has some interesting sharing properties. Two de bruijn index terms like
lam(lam(lam(lam(lam(... var(43)))))) and lam(lam(lam(lam(lam(... var(42)))))) do not share any memory because they differ immediately at the leaf. In the thinning hash cons, they share almost all structure up until the top because the lambdas keep just needing a widening and then thinning of context. They only differ eventually at the actual binding side of the variable.
Basic Hash Cons
This is what one possible definition of a term is. You have some function symbol being applied to an ordered list of arguments.
from dataclasses import dataclass, field
@dataclass
class Term:
f : str
args : list["Term"]
It is nice to reduce memory usage and make fast equality checks. The regular term structure requires traversing it to check equality.
t1 = Term("x", [])
t2 = Term("x", [])
assert t1 == t2 # structurally equal
assert t1 is not t2 # not physically equal. Unneccessary copy.
We can achieve this by basically memoizing the constructor.
I find the clearest way to go about this is to make our own manual “memory space” with integers as “pointers”. The sense in which two trees are structurally equal but not physically equal is too subtle and makes the code harder to read and get right.
By having our interned nodes have a different datatype and by making the child an int identifier rather than the actual subtree, it is much harder to confuse the two things.
from dataclasses import dataclass, field
type Id = int
@dataclass(frozen=True)
class Node:
f : str
args : tuple[Id, ...]
@dataclass
class HashCons:
table : dict = field(default_factory=dict)
nodes : list[Node] = field(default_factory=list)
def app(self, f : str, args : tuple[Id]):
assert isinstance(args, tuple)
node = Node(f, args)
xid = self.table.get(node)
if xid is None:
xid = len(self.nodes)
self.table[node] = xid
self.nodes.append(node)
return xid
else:
return xid
def pp(self, xid : Id):
node = self.nodes[xid]
if not node.args:
return node.f
else:
return f"{node.f}({', '.join(map(self.pp, node.args))})"
hc = HashCons()
x = hc.app("x", ())
x1 = hc.app("x", ())
assert x == 0 # identifier 0
assert x1 == x # We get the same identifier back
y = hc.app("y", ())
assert y == 1
fxy = hc.app("f", (x, y))
assert fxy == 2
# we get same identifier back for same node. No traversal necessary
fxy1 = hc.app("f", (x, y))
assert fxy == fxy1
hc.pp(fxy1)
'f(x, y)'
Offset Hash Cons
It is not always desirable in my opinion to
- Always require hash consing everything
- Require identifiers be simple ints
One probably shouldn’t hash cons something that is going to immediately be destroyed by some simplifier or smart constructor. It may instead be desirable to have a partially hash consed term, where at some depth the ephemeral terms (like Term above) transition into (have as children) interned terms. The appropriate depth might be related to how deep your smart constructors can reach.
As a simple example of this, we can bake in a notion of additive constant offset f(x) + 17 into identifiers. When we offset by a new constant, we don’t have junk in our hash cons, we can immediately just change the offset number and constant fold.
Note we can also have some function symbols marked as linear that can pull the offset annotations up upon application by a smart constructor. This is something like a transfer function for offsets associated with the function symbol. For example double(biz + 7) => double(biz) + 14
Other related structured identifiers one can have are
- strings of identifiers representing associative operations
- multisets of identifiers representing AC operatoins
- polynomials of identifiers
I’ve done similar looking things here:
- https://www.philipzucker.com/ac_hashcons/
- https://www.philipzucker.com/slotted_hash_cons/
- https://arxiv.org/abs/2504.14340 Omelets Need Onions: E-graphs Modulo Theories via Bottom-up E-matching
from dataclasses import dataclass, field
type Id = tuple[int, int] # offset and id
@dataclass(frozen=True)
class Node:
f : str
args : tuple[Id, ...]
def add(a : int, x : Id):
return (a + x[0], x[1])
@dataclass
class OffSetHashCons:
table : dict[Node, int] = field(default_factory=dict)
nodes : list[Node] = field(default_factory=list)
def app(self, f : str, args : tuple[Id]):
node = Node(f, args)
xid = self.table.get(node)
if xid is None:
xid = len(self.nodes)
self.table[node] = xid
self.nodes.append(node)
return (0, xid)
else:
return (0, xid)
def pp(self, x : Id):
off, xid = x
node = self.nodes[xid]
if len(node.args) == 0:
s = node.f
else:
s = f"{node.f}({', '.join(self.pp(arg) for arg in node.args)})"
if off == 0:
return s
else:
return f"{off} + {s}"
hc = OffSetHashCons()
x = hc.app("x", ())
y = hc.app("y", ())
fx = hc.app("f", (add(3,x),))
hc.pp(add(3,x))
hc.pp(add(4, fx))
def double(x : Id) -> Id:
# double smart constructor
off,xid = x
return add(2*off, hc.app("double", ((0, xid),)))
hc.pp(double(add(42,x)))
'84 + double(x)'
Context Hash Cons
A hash cons explained in a certain way is actually a nonsensical goal.
A naive hash cons perfectly destroys notions of context for a term.
That we should expect x + 7 to be the same in let x = 42 in x + 7 and let x = 43 in x + 7 seems completely backwards. What use is that definition? Context kind of matters a lot. Our naive contextless definition of term is bad.
While we may be used to a basic term type that does not have context as a field, this is not a law of the universe. Parse trees often have fields of line and column number. We cannot hash cons similar looking things in one sense without destroying that info. Racket syntax objects contain this source provenance data but also scope data. It is actually very natural for all subterms to be considered unequal since they come from different parts of the input string, or have different full contexts. We may choose to thing some aspects of this context is unimportant, but saying all of it is unimportant is a step too far when bound variables are at play.
from dataclasses import dataclass, field
@dataclass
class ParseTerm:
lineno : int
col : int
f : str
args : list["ParseTerm"]
The variables in scope perhaps are part of terms and should be hashed with them. To delete these things is lying to yourself and you will pay in pain.
@dataclass
class TermInContext:
ctx : list[str]
f : str
args : list["TermIInContext"]
TermInContext([], "lam", [TermInContext(["x"], "var", ["x"])])
TermInContext(ctx=[], f='lam', args=[TermInContext(ctx=['x'], f='var', args=['x'])])
But like the offset hash cons, perhaps it is sensible to factor the ctx as being part of the id rather than the interned parts, since we will often weaken the ctx to lift it into some other place. This achieves more sharing than interning the context inside node.
from dataclasses import dataclass, field
# or frozen set of str?
type Id = tuple[frozenset[str], int]
@dataclass(frozen=True)
class Node:
f : str
args : tuple[Id, ...]
@dataclass
class HashCons:
table : dict = field(default_factory=dict)
nodes : list[Node] = field(default_factory=list)
def app(self, f : str, args : tuple[Id], ctx=[]):
assert isinstance(args, tuple)
node = Node(f, args)
vs = set(ctx)
for arg in args:
vs.update(arg[0])
vs = frozenset(vs)
xid = self.table.get(node)
if xid is None:
xid = len(self.nodes)
self.table[node] = xid
self.nodes.append(node)
return (vs, xid)
else:
return (vs, xid)
def pp(self, xid : Id):
node = self.nodes[xid[1]]
if not node.args:
return f"} |- {node.f}"
else:
return f"} |- {node.f}({', '.join(map(self.pp, node.args))})"
hc = HashCons()
x = hc.app("x", ())
y = hc.app("y", ())
fxy = hc.app("f", (x, y))
fxy1 = hc.app("f", (x, y))
# we get same identifier back for same node. No traversal necessary
assert fxy == fxy1
hc.pp(fxy1)
vx = hc.app("x", (), ctx=["x"])
hc.pp(vx)
def lam(x : str, body : Id):
ctx, id = hc.app("lam", (body,))
return (ctx - {x}, id)
def var(x : str):
return hc.app("var", (hc.app(x, ()),), ctx=[x])
vx = var("x")
hc.pp(lam("x", vx))
hc.pp(lam("x", lam("y", vx)))
def weaken(xs : list[str], e : Id):
ctx, id = e
return (ctx.union(xs), id)
weaken(["y"], lam("x", vx))
# Not the same thing at all
# this is a variable x
#assert vx == (frozenset({"x"}), 0)
# This is a constant x
assert x == (frozenset(), 0)
weaken(["x"], x) # ill formed?
vx
(frozenset({'x'}), 3)
Note that ctx kind of plays the role of a free variable analysis for the Term. As constructed, variables are pushed up from their leaves of use.
Thinning Hash Cons
A thinning hash cons is kind of the same idea but instead we go nameless. We keep the context as weak as possible at all times. This is “co de bruijn” style as shown in McBride’s paper.
First some thinning combinators https://www.philipzucker.com/thin1/ Thinning describe which parts of a context you can toss away when going into a subterm using a bitvector. You can compose these.
type Thin = tuple[bool, ...]
type Id = tuple[Thin, int]
# yeah, python allows this. Neat, huh.
def dom(thin : Thin): return len(thin)
def cod(thin : Thin): return sum(thin)
def thinid(ctx : int) -> Thin: return tuple([True] * ctx)
def comp(thin1 : Thin, thin2 : Thin):
assert cod(thin1) == dom(thin2)
res = []
i = 0
for b in thin1:
if b:
res.append(thin2[i])
i += 1
else:
res.append(False)
assert i == len(thin2)
return tuple(res)
assert dom([True, False, True]) == 3
assert cod([True, False, True]) == 2
assert comp([True, False, True], [False, True]) == (False, False, True)
def widen(thin, x : Id) -> Id:
return (comp(thin,x[0]), x[1])
It ends up being kind of useful to mark if a node adds or destroys an extra bit of context on the left. Traversing down through a lambda adds a new variable into context. In a certain strange kind of way, a variable usage “produces” a slot in context.
@dataclass(frozen=True)
class Node:
f : str
args : tuple[Id, ...]
extra : int = 0 # positive for lam, negative for var. Should this be a thinning? But thinnings can't be positive without opening a can of worms
# positive adds a slot at the beginning of the context
The thinning hash cons largely follows similar lines as those explained above. The app combinator require you weaken the arguments to reconcile their contexts before you apply f. This is pretty unpleasant to use.
@dataclass
class ThinHashCons:
table : dict[Node,int] = field(default_factory=dict)
nodes : list[Node] = field(default_factory=list)
def __post_init__(self):
self.var : Id = self.app("var", (), extra=1)
def app(self, f : str, args : tuple[Id], extra=0):
if args:
arg_thins = [arg[0] for arg in args]
ctx = dom(arg_thins[0])
assert all(ctx == dom(t) for t in arg_thins), "all args must have same thin domain"
# every slot not killed by lambda (negative extra) needs to be used by at least one argument
# because this is true, it is ok to use thinid(ctx) later
for i in range(max(0, -extra), ctx):
assert any(t[i] for t in arg_thins), f"Error in {f} applied to {args}, slot {i} in context is not used"
else:
ctx = 0
arg_thins = []
ctx = ctx + extra
node = Node(f, args, extra=extra)
xid = self.table.get(node)
if xid is None:
# maybe push thin computation in here?
xid = len(self.nodes)
self.table[node] = xid
self.nodes.append(node)
return (thinid(ctx), xid)
else:
return (thinid(ctx), xid)
def lam(self, body : Id):
return self.app("lam", (body,), extra=-1)
def pp(self, x : Id): ...
hc = ThinHashCons()
v = hc.var
v0_1 = v # variable 0 in context size 1
a = hc.app("a", ())
a1 = widen([False], a)
f = lambda x, y: hc.app("f", (x, y))
assert v == ((True,), 0)
assert a == ((), 1)
assert a1 == ((False,), 1)
assert f(a, a) == ((), 2)
assert f(v,v) == ((True,), 3)
assert f(v,a1) == ((True,), 4)
assert f(a1,v) == ((True,), 5)
assert f(v,v) == ((True,), 3)
assert hc.lam(f(v,v)) == ((), 6)
v0_2 = widen([True, False], v) # variable 0 in context size 2,
v1_2 = widen([False, True], v) # variable 1 in context size 2
assert hc.lam(v1_2) == ((True,), 7)
assert hc.lam(v0_1) == ((), 8)
#assert hc.lam(f(v0,v0)) == ((False,), 9) error. Not thinned enough
assert hc.lam(widen([False, True], f(v0_1,v0_1))) == ((True,), 9)
assert hc.lam(f(v0_2,v1_2)) == ((True,), 11)
# f(v0_2, v0_2) # error slot 1 is not used
# f(v1_2, v1_2) # error slot 0 is not used
# hc.lam(v0_2) # error slot 1 is not used
A little bit better is to reconcile automatically. Here I use a global ordering of names to do so. This is also a bit odd. Perhaps an api that uses de bruijn levels or indices would be more natural. I’m not happy with what I have here, but it is actually a challenging problem perhaps worthy of it’s own blog post to figure out something better.
These NamedId are kind of UserIds. The data structure does not really care, but the raw stuff is a terrible api.
type NamedId = tuple[list[str], Id]
# a sorted merge
def reconcile(x : NamedId, y : NamedId) -> Id:
namesx, id1 = x
namesy, id2 = y
assert id1 == id2
assert sorted(namesx) == sorted(namesx)
assert sorted(namesy) == sorted(namesy)
i,j = 0, 0
thinx, thiny = [], []
names = []
while i < len(namesx) and j < len(namesy):
if namesx[i] == namesy[j]:
thinx.append(True)
thiny.append(True)
names.append(namesx[i])
i += 1
j += 1
elif namesx[i] < namesy[j]:
thinx.append(True)
thiny.append(False)
names.append(namesx[i])
i += 1
else:
thinx.append(False)
thiny.append(True)
names.append(namesy[j])
j += 1
assert i == len(namesx) or j == len(namesy)
while i < len(namesx):
thinx.append(True)
thiny.append(False)
names.append(namesx[i])
i += 1
while j < len(namesy):
thinx.append(False)
thiny.append(True)
names.append(namesy[j])
j += 1
return (names, widen(thinx, id1)), (names, widen(thiny, id2))
def napp2(self, f : str, x : NamedId, y : NamedId) -> NamedId:
(names, xid), (names, yid) = reconcile(x, y)
return (names, self.app(f, (xid, yid)))
def napp1(self, f : str, x : NamedId):
(names, xid) = x
return (names, self.app(f, (xid,)))
def nconst(self, f : str):
return ([], self.app(f, ()))
def nvar(self, n : str):
return ([n], self.var)
def nlam(self, v : str, body : NamedId):
(names, bid) = body
assert names[0] == v, f"can only bind first var in ctx: {names[0]}"
return (names[1:], self.lam(bid))
ThinHashCons.napp2 = napp2
ThinHashCons.napp1 = napp1
ThinHashCons.nvar = nvar
ThinHashCons.nconst = nconst
ThinHashCons.nlam = nlam
hc = ThinHashCons()
x = hc.nvar("x")
y = hc.nvar("y")
a = hc.nconst("a")
hc.napp1("f", x)
fxy = hc.napp2("f", x, y)
fyx = hc.napp2("f", y, x)
hc.nlam("x", fxy)
#hc.nlam("y", fyx)
#def subst(self, )
(['y'], ((True,), 5))
Bits and Bobbles
The thinning hash cons is more “local” in some sense than using de bruijn indices and I think this is what (if I’m right) makes it the right stepping stone to a kind of alpha invariant egraph.
The thinning hash cons is kind of a slotted hash cons where you have ordered binders / don’t play the permutation game. https://www.philipzucker.com/slotted_hash_cons/ . I think the thinning hash cons is (as crazy as this sounds) a simpler thing.
https://pavpanchekha.com/blog/egg-bindings.html Thinning hash cons do have a flavor of “letting the succ float”, unmooring the de bruijn indices from inside the Var constructor and letting them appear anywhere in the term .
type nat = Succ of nat | Zero
type term =
| Lam of term
| Var of nat
| App of term * term
type term1 =
| Lam of term1
| VZero
| VSucc of term1
| App of term1 * term1
The ContextTerm is kind of like a well scoped dependently typed Expr Gamma, but we push the dependent indices into regular fields and make the type checks into dynamic asserts.
Hashing modulo alpha equivalence is an interesting topic
https://arxiv.org/abs/2105.02856 Hashing Modulo Alpha-Equivalence https://arxiv.org/abs/2401.02948 Hashing Modulo Context-Sensitive α-Equivalence
I think what I’ve described above is pretty differetn from the variable mapping tree idea. The mapping tree idea is compelling, but when you start doing egraph stuff, the manipulations of subterms and the maps need to be correlated and the whole thing falls apart.
You can visualize the thinning hash cons as little threads (the thinning diagrams) running down the term. The edge between parent and child is “fattened” to thinning threads.
On the one hand, there is the perspective that de bruijn indices exist https://en.wikipedia.org/wiki/De_Bruijn_index . They label a variable by how many binders must be crossed to get to it’s binding site. A closed lambda term represented by de bruijn indices is structurally canonical, so what is the problem?
Well, yeah, but you want to be at the very least temporarily working with open terms and moving de bruijn indexed terms around requires shifting indices as the number of binders traversed changes. The labelling scheme is pretty non local and non stable on changing terms. It’s spooky action at a distance.
It feels desirable to have a scheme that doesn’t change
https://arxiv.org/pdf/1807.04085 Everybody’s Got To Be Somewhere
I can’t really read this paper. Agda is a bit too foreign for me and the category theory one notch too dense. But I get snippets here and there from it. I think it has much of what I’m writing today and more.
First I’ll show a basic hash cons so you can recognize the twists I’m adding as twists. Then as an example, a hash cons that bakes in offsets into it identifiers as more elementary example of “fat/structured ids” A little diatribe on whether some notion of context should have been a field in the standard Term datatype all along. Finally adding in thinnings as annotations.
Thinned Hash Conses and Co de Bruijn
type NamedId = tuple[list[str], Id]
def weaken(ctx : list[str], e : NamedId) -> NamedId:
i = 0
ctx0, (thin0 , id) = e
assert len(ctx0) == len(thin0)
thin = []
for name in ctx:
if i < len(ctx0) and name == ctx0[i]:
thin.append(thin0[i])
i += 1
else:
thin.append(False)
assert i == len(ctx0)
return (ctx, (tuple(thin), id))
def var(name : str) -> NamedId:
return ([name], ((True,), 0))
x = var("x")
y = var("y")
assert weaken(["x", "y"], x) == (["x", "y"], ((True, False), 0))
assert weaken(["y", "x"], x) == (["y", "x"], ((False, True), 0))
assert weaken(["y", "x"], y) == (["y", "x"], ((True, False), 0))
def namelam(self : ThinHashCons, name : str, body : NamedId) -> NamedId:
ctx, tid = body
assert ctx and ctx[0] == name, f"expected {name} to be first in context {ctx}"
return ctx[1:], self.lam(tid)
ThinHashCons.namelam = namelam
#def reconcile(ctx : list[str], es : list[NamedId]) -> tuple[NamedId, ...]:
# # check that all es have same thin domain, and that it matches ctx
# res = []
def napp(ctx : list[str], f : str, args : list[NamedId]) -> NamedId:
args = [weaken(ctx, arg)[1] for arg in args]
# and maybe filter down to actually used pieces of context.
# type NamedId = tuple[list[str], Thin, Id]
return ctx, hc.app(f, tuple(args))
class ExprRef:
#ctx : list[str] # could be a part of hc? If we want reconciling
id : Id
names : list[str]
hc : ThinHashCons
def weaken(ctx : list[str], e : ExprRef): ...
def reconcile(ctx : list[str], es : list[ExprRef]): ...
type Id = tuple[Thin, int] # thin and id
#@dataclass(frozen=True)
#class Node:
# f : str
# args : tuple[Id, ...]
@dataclass
def Var(ctx : list[str], name : str):
...
def reconcile(args : tuple[UserId, ...]):
@dataclass
class ThinHashCons:
table : dict[Node,int] = field(default_factory=dict)
nodes : list[Node] = field(default_factory=list)
def app(self, f : str, args : tuple[Id]):
if args:
ctx = dom(args[0][0])
assert all(ctx == dom(arg[0]) for arg in args), "all args must have same thin domain"
else:
ctx = 0
node = Node(f, args)
xid = self.table.get(node)
if xid is None:
xid = len(self.nodes)
self.table[node] = xid
self.nodes.append(node)
return (thinid(ctx), xid)
# var should have
var : Id = ([True], self.app("var", []))
def lam(body : Id):
return self.app("lam", (body,))
Cell In[3], line 19
@dataclass
^
IndentationError: expected an indented block after function definition on line 16
The co de bruijn manual thinning interface is painful. Even de bruijn indices are an easier interface to use. de bruijn index interface
type Ctx = list[int] # which de bruijn indices still survive
type UserId = tuple[Ctx, Id]
def vardb(n : int) -> UserId:
return
def lamdb(body : UserId) -> UserId:
return
def appdb(f : str, args : tuple[UserId, ...]) -> UserId:
# automatically reconcile the arguments.
type NameCtx = tuple[list[str], list[str]] # a name ordering and names correspond to thins
type UserId = tuple[NameCtx, Id]
def vname(nameorder, name : str) -> UserId:
return ([name], self.app("var", []))
def appdb(f : str, args : tuple[UserId, ...]) -> UserId:
def lam(name : str, body : UserId) -> UserId:
# remove prefix up to name from nameorder.
return self.app("lam", (body,))
def perm(ctx : NamedCtx, nameorder : NamedCtx):
# you can
type Ctx = dict[str, int] # which variable is which id
# type Ctx = list[str | None] ordered names, with inaccessibles also. But
# type Ctx = list[str]
type UserId = tuple[Ctx, Id]
There is a debate about whether to have a single node type or special Var and Binder types
Every subtree of as term appears in a unique position. It is an extreme stance a priori to think that every subtree is “equal” to all the others. This is not the case for example for common syntax trees coming out of parser. Each tree comes from different positions inside the input string. Parse trees are often annotated with these line columns numbers and other metadata. To hash cons this parse tree would destroy all this contextual data and is a violent act.
Racket syntax vs datum. https://docs.racket-lang.org/guide/stx-obj.html Also part of the context there is the information needed for macro hygiene and name resolution. Terms should have their scopes / contexti n them sometimes
Well scoped syntax in agda also has scope as part of the term. It is always (?) possible to take the dependently indexed data, make that ordinary data instead, and defer checking to runtime. In this form, the well scoped term technology becomes terms with embedded context. This is a more mundane form of dependent type tricks. Sure, you can make a list that carriers it’s size in each cons cell. That’s a dependent vector. Trying this out could probably be a blog post of it’s own. Wintess data oriented programming rather than proof relevant dependent types.
A naive hash cons is perfect contextual destruction and to try and hack your way into recovering context after this violent act is like trying to sweep spilled milk back into broken crockery.
On the other hand, it is always a coherent goal to reduce memory usage, make fast equality checks, and avoid/memoize computation.
The string location information like filename, lineno, and column are interestingly kind of close to a notion of context.
The idea that somehow x + 7 in these two strings
let x = 42 in x + 7
let x = 56 in x + 7
are obviously and always deduplicated seems ludicrous to me. It’s a choice and a questionable one.
That’s actually interesting. A context object
def var(ctx, name): if name in ctx: return ctx[name] else: return weaken(ctx, hc.var(name)) def lam(name, body): ctx, bodyid = body ctx1 = {k:v for k,v in ctx.items() if k != name} return (ctx1, hc.lam(body))
There is something funky that we are constructing terms, which happens naturally bottom up, but the context is natrually collected top down
let the succ float
These datatypes are not isomorphic, but they are related by pushing around constructors.
type nat = Succ of nat | Zero
type term =
| Lam of term
| Var of nat
| App of term * term
type term =
| Lam of term
| VZero
| VSucc of term
| App of term * term
type term =
| Lam of tid
| VZero
| App of tid * tid
and tid = nat * term (* compact many succ into a single nat *)
type term =
| App of str * term list
| Offset of int * term
vs
type term =
| App of str * tid list
and tid = int * term
https://people.cs.nott.ac.uk/psztxa/publ/ctcs95.pdf
(* The lifted succ appears there *)
type weak = Wid | W1 of weak | W2 or weak
type weakterm =
| Lam of term
| VZero
| VSucc of term
| App of term * term
| W1 of term
| W2 of term
This is quite hard to use correctly. So wrapping with a named api is probably good.
type NamedId = tuple[list[str], Id]
type Id = tuple[list[tuple[str, bool], int]]
We could kind of use locally nameless discipline and generate fresh names when we go under binders and when we build the first time.
type DBId = tuple[list[int], Id]
This hash cons has even more powerful reduction capabilities than de bruijn indices. And you don’t have to traverse the term to achieve shifts, just the thinning annotation
var(“x”) and var(“y”) make different hashings
var(0) and var(1) do also
lam(lam(lam(lam(lam(lam(…v(30))))))) lam(lam(lam(lam(lam(lam(…v(31))))))) achieve a lot more sharing. de bruijn index shares nothing. thinning completely shares term up until 30 up.
lam(var(“x”)) lam(var(“y”)) are completely unsared de bruijn shares them
but there is no sharing in lam(lam(lam(var(2))))` lam(lam(lam(var(1)))) even though there is some similarity there.
foo(a) and bar(a) do share the a even though they are different. bar(foo(a)) biz(foo(a))
You don’t have to reintern to carry a term to a new context. de bruijn does (all variable that point outside the term need to be shifted for each binder you cross).
It makes sense perhaps to not intern anything that might be changed by a future smart constructor. So only truly intern after the finite depth of pattern of all smart constructors has been reached. Or you can do a more fine grained thing.
The concept of a basic term comes from high school algebra.
When calculus comes into play, the context becomes a very important part of what a term is.
As crucial as a term’s type. We tend to consider the type as being implied by the function symbol rather than an explicit field
It’s interesting to consider how to do this in a dependently typed language with well scoped syntax. I suppose you need a dependent hashmap to hash cons into and use indexed Ids
There’s some related questions and problems in union finds. You’d want the union find to return evidence of the relationship. find a = {x : Id | R a x} is_eq(a,b) -> Option (R a b)
True pointer equality is prbably inconstient to have. So you need to build your own pure Ref a system
The key monad
The thinnings kind of a play a role as a “free variable analysis”
People usually do a “free variable analysis” in a named representation, but it seems cogent in de bruijn indices also. The collection of indices appearing in the expression that are not bound by a binder. One has to shift the analysis as one transfers (the “transfer function”) it from below a lambda to above a lambda.
Is there a simpler hash cons example where it is reasonable to have a distinction between inner id and user id? Names are kind of perfect, because they aren’t semantically meaningful but they are tags to refer to stuff easily.
Each kind of binder might want it’s own thinnings to work with. There is no reason for the indices of summation to interfere or interface with the indices of lambdas or min/max or forall. It is also convenient though to just use a single thinning for all of them.
Gensyming names into a global order might kind of work? lam(gensym(), )
@dataclass
class TypedTerm:
typ : str
f : str
args : list["TypedTerm"]
TypedTerm("bool", "=", [TypedTerm("int", "x", []), TypedTerm("int", "y", [])])
@dataclass
class TypedTerm2:
f : tuple[str, int, str] # name arity, type
args : list["TypedTerm"]
@dataclass
class TypedTerm3:
f : tuple[str, list[str], str] # name, type of args, type output
args : list["TypedTerm"]
Showing Python AST equality Has context in it
import ast
e1 = ast.parse("1", mode="eval")
e2 = ast.parse("(1)", mode="eval")
e3 = ast.parse("1 + 0", mode="eval")
def ast_eq(a, b):
return ast.dump(a) == ast.dump(b)
def ast_eq2(a, b):
return ast.dump(a, include_attributes=True) == ast.dump(b, include_attributes=True)
def ast_eq3(a, b):
return eval(ast.unparse(a)) == eval(ast.unparse(b))
assert not e1 is e2
assert ast_eq(e1, e2)
#ast.dump
#ast.dump(e2, include_attributes=True)
ast_eq2(e1,e2)
ast_eq(e1, e2)
print(ast.dump(e1, include_attributes=True))
print(ast.dump(e2, include_attributes=True))
assert not ast_eq2(e1, e2)
assert ast_eq3(e1, e2)
assert ast_eq3(e1, e3)
assert not ast_eq(e1, e3)
ematching